
Les raisons d’une mauvaise qualité de données peuvent être variées. Entre les différentes étapes d’ingestion des données, de leur transformation et de leur exploitation dans des dashboards ou des analyses, les erreurs peuvent arriver à plusieurs endroits.
La semaine dernière, j’ai écrit un article sur l’importance d’une bonne Data Quality dans lequel je définissais ce que c’était et quelles étaient les conséquences d’une mauvaise qualité de données dans votre entreprise. Je vous invite à aller le consulter avant de lire celui-ci.
Selon moi, il y a cinq étapes essentielles à mettre en place pour maintenir une bonne qualité de données.
Étape 1 : Mesurer la Data Quality
J’ai une conviction assez forte en matière de données : pour améliorer quelque chose, peu importe ce que c’est, il faut d’abord le mesurer. C’est important pour savoir où on en est mais aussi pour constater l’évolution suite aux mesures que nous mettons en place.
Penser à un outil de suivi de la Data Quality a un effet secondaire bénéfique : cela clarifie la notion de Data Quality dans l’esprit de tous et en réfléchissant à un tel outil de monitoring, on pense déjà aux solutions qu’on peut mettre en place.
Certains aspects sont plus faciles à mesurer que d’autres, et la Data Quality peut être assez complexe à suivre. Cependant, on peut déjà identifier plusieurs indicateurs qui peuvent donner une idée assez claire de l’état de notre plateforme de données :
- Le nombre de tickets d’incident qui concernent la qualité des données.
- Le nombre de runs de la pipeline qui échouent ou génèrent des avertissements.
- La consultation des dashboards : on peut supposer que des dashboards non consultés sont de mauvaise qualité (même si ce n’est pas l’unique raison).
- Le Time-to-Insight de votre équipe Data : une mauvaise qualité de données entraîne régulièrement une augmentation du temps de réponse aux besoins métiers (plus d’allers-retours entre les composantes de votre équipe Data, plus de transformations manuelles pour corriger les données, plus d’investigations pour s’assurer de la qualité, etc.)
Ces indicateurs de base seront complétés par d’autres que nous ajouterons dans les quatre étapes suivantes.
Exemple du dashboard de Monitoring d'Elementary pour dbt
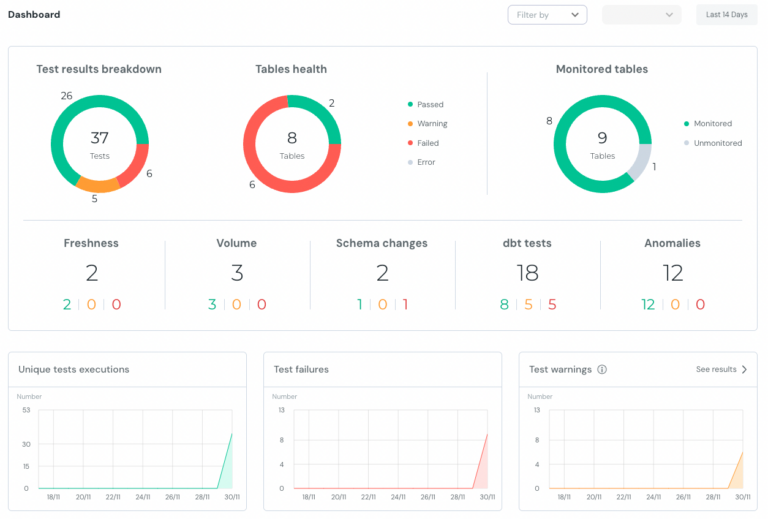
Étape 2 : Contractualiser les données à transformer
C’est une pratique que je vois peu, mais qui me semble essentielle. J’observe de nombreuses entreprises dans lesquelles les Data Engineers remontent des données que les Analytics Engineers ou Data Analysts vont ensuite transformer ou exploiter, sauf que ces derniers ont régulièrement des questions sur ces données qu’ils reçoivent :
- À quoi correspondent-elles concrètement ?
- Pourquoi un même objet apparaît-il en double ?
- Pourquoi la table n’a-t-elle pas été rafraîchie depuis deux jours ?
- Quel est le format de date pour les champs de la table ?
- Etc.
Je remarque que les utilisateurs de ces données sources ont généralement deux réflexes lorsqu’ils sont confrontés à de telles situations : ils vont soit demander au Data Engineer, soit ils vont sentir qu’ils ont déjà posé trop de questions au DE, donc ils vont explorer la table pour répondre eux-mêmes à ces questions. Et souvent, les réponses auxquelles ils arrivent ne sont pas les bonnes. Et ces erreurs d’interprétation peuvent conduire à des dysfonctionnements dans la pipeline de données.
Cela aurait pu être évité en spécifiant clairement les différentes sources de données mises à disposition :
- Nom de la table.
- Description de la table.
- Noms, descriptions et types des champs.
- Emplacement de la table.
- Fréquence de rafraîchissement attendue.
- Personnes ou équipes qui ont accès aux données.
- Etc.
Cela peut prendre plusieurs formes, comme une simple page Notion qui regroupe ces informations ou être intégré directement dans le projet dbt. Une bonne pratique que j’aime bien, c’est de demander au Data Engineers de créer les modèles des données sources auxquels auront accès les Analytics Engineers et d’accompagner ces modèles du contrat associé.
À rajouter dans le dashboard Data Quality :
- La couverture des Data Contracts : combien de sources mises à disposition sont contractualisées ?
Étape 3 : Une bonne stratégie de tests
Aujourd’hui, il semble inenvisageable de développer une application, un site web ou n’importe quel logiciel sans mettre en place une stratégie de tests qui assure la qualité du produit développé. Nous voyons encore beaucoup de projets Data sans le moindre test.
Traitez votre Data comme un produit ! Et mettez une stratégie de tests en place.
Maintenant que nous avons des Data Contracts qui spécifient ce qui est attendu comme données en entrée, nous pouvons mettre en place des tests qui vérifient ces spécifications. Sur cette étape de validation des données sources, nous pouvons également réaliser des tests d’anomalies : nous allons tester les volumes ou les valeurs des données remontées et les comparer aux données obtenues les jours ou semaines précédents. Un volume nettement plus faible que celui observé les derniers jours peut indiquer des erreurs.
Les tests ne s’arrêtent pas là ; il faut également tester les différentes transformations que nous développons :
- Tests unitaires des modèles.
- Tests d’anomalies des valeurs.
- Tests sur les valeurs null d’une tables.
- Tests sur les clés primaires et étrangères.
- etc.
Et cela implique également la mise en place d’une pipeline CI/CD qui va tester les modèles de données à chaque déploiement afin de s’assurer que ce qui est mis en production est fonctionnel.
Un système d’alerting peut (doit ?) aussi être mis en place afin d’être proactif sur la résolution des erreurs et éviter que ce soient les équipes métiers qui nous remontent les anomalies dans les données (rappelons que l’un des principaux objectifs de maintenir une bonne Data Quality est de rassurer les utilisateurs finaux sur les chiffres qu’ils consultent).
version: 2
sources:
- name: jaffle_shop
database: raw
freshness: # default freshness
warn_after: {count: 12, period: hour}
error_after: {count: 24, period: hour}
loaded_at_field: _etl_loaded_at
tables:
- name: customers # this will use the freshness defined above
- name: orders
freshness: # make this a little more strict
warn_after: {count: 6, period: hour}
error_after: {count: 12, period: hour}
# Apply a where clause in the freshness query
filter: datediff('day', _etl_loaded_at, current_timestamp) < 2
- name: product_skus
freshness: # do not check freshness for this table
Exemple de tests sur la freshness des données dans dbt
À rajouter dans le dashboard Data Quality :
- La couverture des tests.
- Le taux de succès des tests.
Étape 4 : Une modélisation efficace
Beaucoup d’erreurs que je vois proviennent d’une mauvaise utilisation des données par les équipes métier. Cela peut provenir de deux facteurs : un manque de compétences techniques chez l’utilisateur (voir l’étape suivante) ou alors des données mises à disposition qui ne sont pas claires et compliquées à utiliser.
De la même manière que nous avons demandé aux Data Engineers de spécifier complètement les données qu’ils mettaient à disposition, nous devons demander aux Analytics Engineers de documenter ce qu’ils mettent en place. Et il leur incombe également de produire une modélisation claire et facile à utiliser pour les utilisateurs métiers.
Je vois de nombreux modèles de données très normalisés qui sont fastidieux à utiliser. Selon moi, une modélisation en étoile est très efficace et facilement utilisable.
Pour la documentation, cela peut se faire via un Semantic Layer ou alors un Data Catalog.
Étape 5 : Former vos collaborateurs
Beaucoup d’erreurs dans les données proviennent d’erreurs humaines, causées soit par un manque de concentration, soit par un manque d’outils adaptés, soit par un manque de compétences techniques. Aujourd’hui, de nombreux Analytics Engineers présentent des lacunes en modélisation, en optimisation de requêtes SQL ou concernant les bonnes pratiques. Et cela augmente naturellement le risque d’erreurs dans la pipeline de données.
Pour éviter cela, la solution est assez simple : il suffit de former votre équipe Data. Mais il n’est pas toujours nécessaire de faire appel à un formateur externe ou de les inscrire à une formation externe. Je remarque souvent que les connaissances sont déjà là en interne et qu’il suffit de les partager entre les équipes. Ce que je conseille souvent (quand c’est possible) à mes clients, c’est d’organiser des formations entre les différentes équipes :
- Les Analytics Engineers peuvent préparer des exercices pour les Data Analysts pour apprendre à manipuler les données métier.
- L’équipe des développeurs peut présenter les bonnes pratiques qu’ils mettent en place sur leur produit aux Data Engineers pour qu’ils puissent les adopter.
- L’équipe de Data Engineers peut présenter le développement d’un connecteur aux Analytics Engineers afin qu’ils comprennent mieux l’origine des données qu’ils manipulent.
- Etc.
Tout cela a pour effet secondaire d’améliorer la communication entre les équipes et, en préparant une formation/présentation, on se rend compte beaucoup plus facilement des blocages que les apprenants peuvent rencontrer, ce qui permet de réfléchir plus facilement à des solutions.
Cependant, cela n’est pas toujours possible et avoir un regard extérieur est parfois plus judicieux. C’est ce que j’ai eu l’occasion de faire dans différentes entreprises en intervenant pour présenter les bonnes pratiques de l’Analytics Engineering et également au Wagon, où je forme de futurs Data Analysts.
À rajouter dans le dashboard Data Quality :
- Taux de formation dans l’équipe Data.
Ce sont, selon moi, les 5 étapes essentielles à mettre en place dans une stratégie de Data Quality. Je sais que ça n’est pas la partie la plus marrante du travail et qu’on a la sensation de ne rien produire de concret dans ce genre de projet. Mais cela va vous faire gagner énormément de temps à l’avenir, va vous amener de la sérénité au quotidien et va permettre de construire une réelle confiance chez vos utilisateurs métier.
Je vais prochainement détailler ces différentes étapes mais si vous avez déjà des questions sur le sujet, je vous laisse me contacter, ce sera un plaisir d’échanger avec vous sur le sujet et de vous apporter de premières solutions à vos problématiques.