
Maintenir une bonne qualité des données est essentiel à tous les niveaux. Bien que l’envie de développer rapidement des transformations pour répondre aux besoins métiers soit forte, il est crucial de veiller à la qualité tout au long du pipeline. Sinon, vous risquez de perdre la confiance des équipes métier.
Avec dbt, de nombreuses méthodes permettent de renforcer nos transformations. Aujourd’hui, je vais vous présenter un outil axé sur la détection des anomalies. Sans un tel outil, les erreurs sont souvent repérées par les équipes métier, ce qui peut nuire à votre crédibilité. Grâce à l’outil que je vais vous présenter, vous pourrez anticiper ces problèmes, corriger les erreurs rapidement, et préserver la réputation de votre équipe tout en restant confiant dans les données que vous livrez.
Les fonctionnalités d'Elementary
L’outil que je vais vous présenter aujourd’hui est un package dbt nommé Elementary. Il permet de facilement mettre en place des tests pour détecter les anomalies :
- De volume : détection d’une table alimentée avec moins de lignes que d’habitude.
- De fraîcheur : détection d’une table alimentée moins régulièrement que d’habitude.
- De contenu : détection d’une table contenant des valeurs anormales comparées à d’habitude.
- De changement de schéma : détection d’une table dont le schéma change (ajout ou suppression d’une colonne, changement de type de colonne, etc.).
Comme vous le voyez, la logique principale de ce package est de comparer les tables avec ce qui se passe habituellement, ce qui lui permet de déterminer s’il y a une anomalie ou non.
Ce sont les fonctionnalités de base, mais Elementary propose également un outil cloud offrant les services suivants :
- Suivi des résultats de tous les tests que vous avez développés (tests d’anomalies mais aussi les autres tests développés dans dbt).
- Lineage au niveau des colonnes.
- Mise en place d’alertes.
- Dashboard pour suivre la qualité de vos données.
- Suivi des temps d’exécution de vos transformations.
- …
Dans cet article, je vais vous faire une rapide présentation de ces différentes fonctionnalités, avant de partager mon opinion sur cet outil, que je trouve très puissant malgré certaines limites.
Installation
L’installation d’Elementary va se faire en deux étapes : la première est d’installer le package dbt qui va nous permettre de mettre en place les différents tests de détection d’anomalies et la seconde est de mettre en place le dashboard de monitoring qui va nous permettre d’exploiter, entre autres, les resultats de ces tests.
Installation du package dbt-elementary
Afin d’installer le package Elementary et de profiter de ses fonctionnalités, il faut suivre la documentation du package, mais c’est un processus très similaire à l’installation classique d’un package dbt :
- Ajouter au fichier
packages.yml:
packages:
- package: elementary-data/elementary
version: 0.16.0
- Exécuter
dbt deps - Ajouter au fichier
dbt_project.yml:
models:
elementary:
+schema: "elementary"
Cela permettra de stocker toutes les tables générées par Elementary dans un schéma spécifique. Ces tables contiennent les résultats des différents tests, les temps d’exécution des modèles, etc. Ce sont toutes les données qui seront ensuite réutilisées dans le dashboard de monitoring.
- Exécuter
dbt run --select elementary.
Une fois ces étapes effectuées, à chaque exécution d’un dbt build ou dbt test, les tests Elementary que l’on va définir seront exécutés et leurs résultats seront stockés dans les tables dédiées.
Installation du dashboard de monitoring
Afin de visualiser les résultats de nos tests et toutes les autres informations dans le dashboard proposé par Elementary, il y a deux possibilités :
- Souscrire à l’offre Elementary Cloud.
- Utiliser la version Open Source.
Pour cette démonstration, j’ai utilisé la version Open Source que j’héberge en local. La documentation explique comment l’installer.
Il existe une troisième façon d’exploiter ces données, que je présenterai à la fin de cet article.
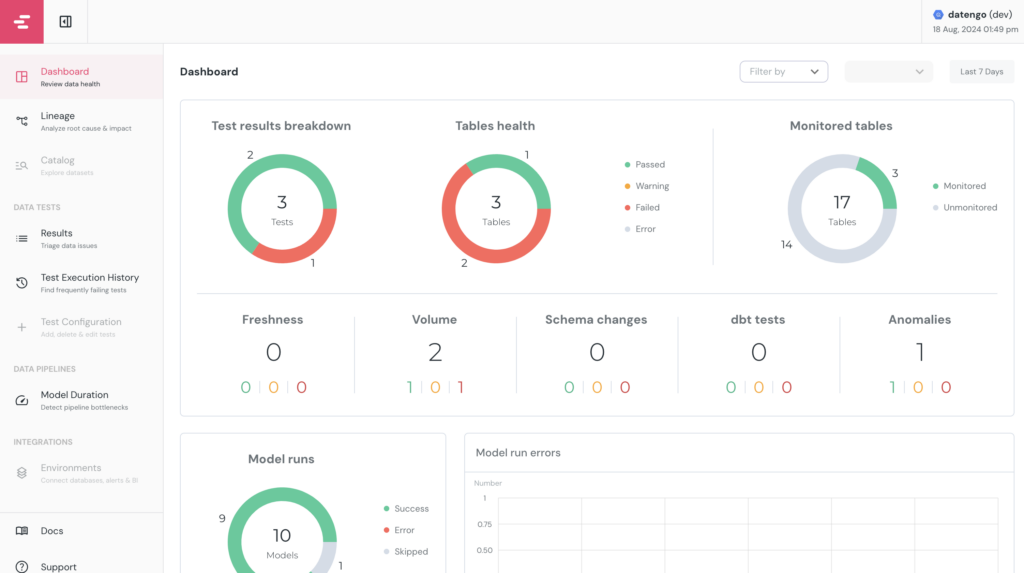
Mise en place des tests Elementary
Maintenant que tout est installé, nous pouvons mettre en place nos premiers tests pour détecter des anomalies dans nos données.
Détection d’anomalies de volume
La détection d’anomalies de volume est essentielle pour identifier des problèmes tels que des volumes de données anormalement élevés ou faibles, ce qui peut indiquer des erreurs lors de l’alimentation.
Dans notre exemple, une équipe de Data Engineers est responsable d’alimenter une table d’audience de notre site web. Cette table récupère les données de Google Analytics et, chaque jour, elle envoie différentes vues des performances du site. Il s’agit d’une tâche très régulière : nous attendons chaque jour le même nombre de lignes.
Pour cela, nous allons configurer un test d’anomalie sur le volume de données.
models:
- name: stg_ecommerce__audience
config:
elementary:
timestamp_column: _synced_at
tests:
- elementary.volume_anomalies:
anomaly_sensitivity: 2
training_period:
period: day
count: 30
Comme pour les autres tests dbt, on configure les détections d’anomalies dans les fichiers yml configurant les modèles. En déclarant le test, nous avons de nombreuses possibilités de configuration. Dans notre exemple, nous définissons le champ de type date sur lequel le test devra s’appuyer (timestamp_column), la sensibilité du test (anomaly_sensitivity, plus le chiffre est bas, plus c’est sensible et on s’attend à être proche des données historiques) et la période de l’historique sur laquelle il va se baser pour déterminer s’il y a une anomalie (training_period).
Il existe beaucoup d’autres configurations disponibles que je vous laisserai découvrir dans la documentation du projet.
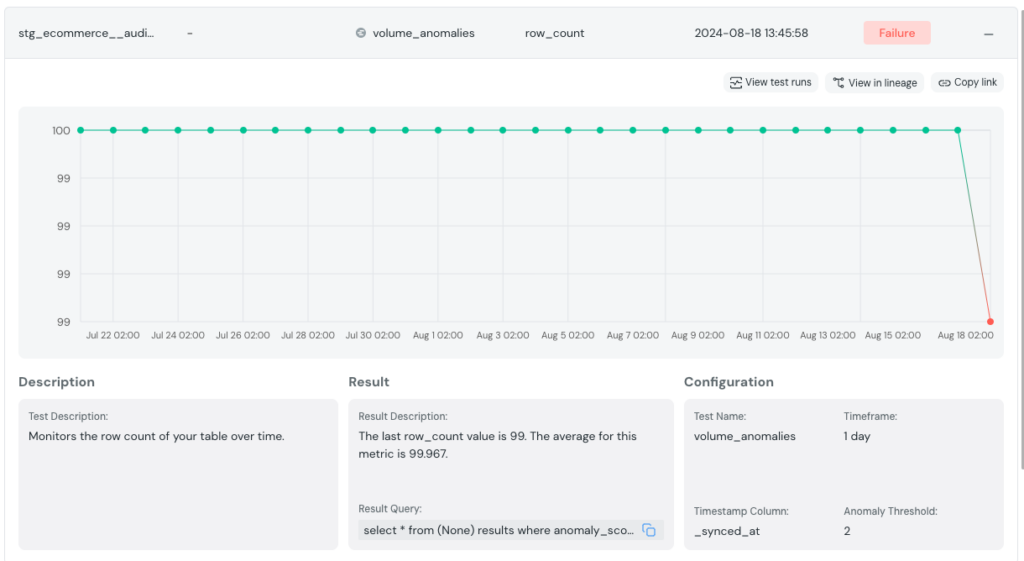
Ici, nous voyons que le test détecte une anomalie pour la veille, car 99 lignes ont été observées comparées aux 100 qui sont alimentées quotidiennement. Une alerte a été lancée, nous avons pu prévenir les utilisateurs de cette donnée et investiguer le problème avec l’équipe en charge de l’alimentation de cette table.
Détection d’anomalies dans les données
Un autre type de test intéressant à réaliser est celui qui vérifie le contenu des données.
Par exemple, nous sommes responsables des données d’un site de e-commerce. Nous voulons nous assurer que les montants enregistrés ne sont pas erronés. Ce que nous pouvons faire ici, c’est vérifier la moyenne des montants dépensés par nos clients. Bien entendu, cette moyenne varie d’un jour à l’autre, mais elle ne devrait pas changer drastiquement par rapport aux jours précédents.
models:
- name: stg_ecommerce__orders
config:
elementary:
timestamp_column: order_date
columns:
- name: order_amount
tests:
- elementary.column_anomalies:
timestamp_column: order_date
training_period:
period: day
count: 30
column_anomalies:
- average
Ce test va checker les anomalies de la colonne order_amount. Pour cela, il va se baser sur les 30 derniers jours (training_period) et comparer la moyenne de ces 30 derniers jours avec la dernière journée (column_anomalies).
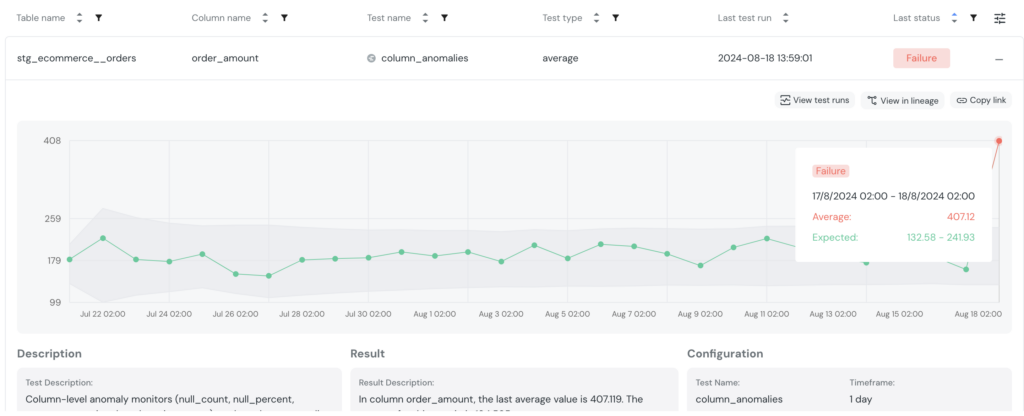
Ce que l’on observe ici, c’est une valeur anormalement élevée. Après investigation, on constate que de nombreuses commandes ont été enregistrées en double. C’est un problème que l’équipe métier aurait pu identifier rapidement, mais ici, elle aura été avertie en amont qu’il y a une erreur, et le problème pourra être rapidement corrigé.
Détection d’un changement de schema
Dans les deux tests précédents, nous avons testé les données en entrée. Maintenant, nous allons nous assurer que nos transformations n’introduisent pas d’erreurs dans les modèles. L’une des erreurs qui peut survenir est un changement de schéma.
Imaginons que nous créons un nouveau modèle et que, pour cela, nous devons modifier légèrement un modèle existant qui est déjà utilisé ailleurs.
La détection d’un changement de schéma permet de nous assurer qu’un champ n’a pas changé de type au cours de ces modifications.
models:
- name: kpis_orders
tests:
- elementary.schema_changes:
tags: ["elementary"]
config:
severity: warn
Ici, il n’y a rien de plus à ajouter à la configuration. À chaque exécution, il va comparer le schéma de cette table à celui des exécutions précédentes.
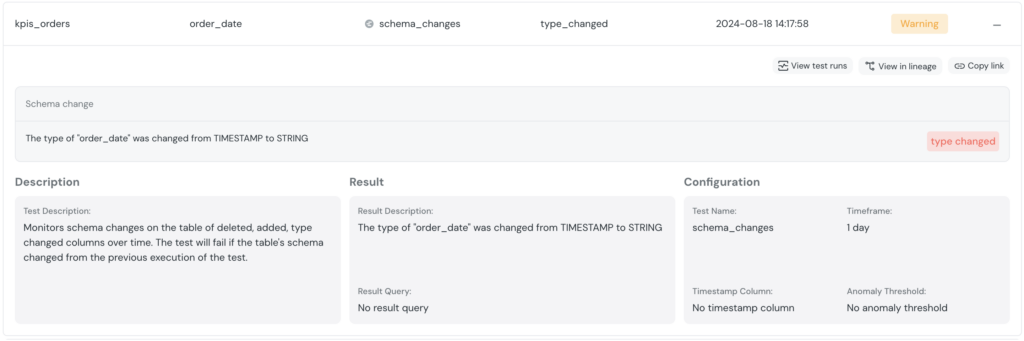
Ici, on voit que la colonne order_date a vu son type changer. Après une rapide investigation, on voit que c’est une chaine de caractère qui a oublié d’être casté en TIMESTAMP dans un des modèles modifiés.
Elementary : Un outil pussant
La détection d’anomalies avec Elementary est très puissante. Si les tests sont bien pensés et configurés, il est possible de prévenir efficacement les erreurs. Comme ces tests ont un coût, je conseillerais de ne les développer, dans un premier temps, que sur les tables critiques.
En plus d’être un simple outil permettant de mettre en place des tests avancés, c’est un outil qui va réellement vous orienter vers une stratégie de maintien d’une bonne qualité des données.
Une fonctionnalité qui aurait été puissante serait justement de pouvoir détecter automatiquement les tables critiques et de générer un premier test en analysant la table. Je pense que c’est tout à fait possible en se basant sur toutes les métadonnées disponibles dans dbt ainsi que sur le Data Lineage.
Limite : l’exploitation des résultats
Dans tout ce que je vous ai présenté, ce qui me gêne le plus et que je trouve limitant, c’est l’exploitation des résultats des différents tests. Le dashboard Elementary nous offre de nombreuses possibilités, mais j’aimerais pouvoir y ajouter des données propres à mon organisation. Par exemple, j’aimerais pouvoir filtrer le dashboard par rapport aux dashboards finaux impactés au sein de mon entreprise. Si j’ai un dashboard “Acquisition Report”, j’aimerais voir les résultats des tests des différents modèles qui participent à ce dashboard.
En outre, avoir l’outil de monitoring d’Elementary en plus de votre outil de Data Visualization habituellement utilisé au sein de votre entreprise peut être dommageable, car cela multiplie les outils utilisés.
Pour répondre à ces besoins, il est heureusement possible de récupérer les résultats des tests, car ils sont stockés dans différentes tables du schéma Elementary. Il est donc possible de les exploiter de votre côté dans votre propre dashboard. Je vous expliquerai un exemple sur lequel j’ai travaillé dans un futur article.
D’ici là, n’hésitez pas à me contacter si vous avez la moindre question sur l’utilisation de cet outil !