
Deux objectifs essentiels dans le développement de pipelines de données sont de minimiser les ressources nécessaires (en termes de temps et de coûts) tout en maintenant une excellente qualité des données. dbt offre de nombreux outils pour atteindre ces deux objectifs. L’un des outils que je souhaite vous présenter aujourd’hui est le modèle incrémental. Ce type de modèle permet de réduire considérablement les ressources requises pour les transformations. Cependant, s’il est mal utilisé, il peut également avoir un impact très négatif sur la qualité des données.
Dans cet article, je vais vous expliquer le concept des modèles incrémentaux, en détaillant leur utilité et leur mise en œuvre. Je partagerai également quelques conseils pour vous aider à rendre vos transformations de données plus fiables et performantes.
A quoi ça sert ?
Les modèles incrémentaux sont indispensables pour optimiser les performances de vos pipelines de données. Ils permettent de réduire considérablement les temps de traitement en ne traitant que les nouvelles données ou celles qui ont été modifiées depuis la dernière exécution. Cela permet de résoudre, entre autres, les problèmes de goulots d’étranglement, où tous les threads sont en attente de l’exécution correcte des modèles avant de pouvoir démarrer. Les modèles incrémentaux sont un outil puissant pour limiter le temps d’exécution des modèles critiques.
En plus de l’optimisation du temps, les modèles incrémentaux permettent également d’économiser des ressources, notamment en réduisant les coûts de calcul en ne traitant que les nouvelles données, plutôt que de recharger toutes les données à chaque exécution. On observe que les coûts des modèles incrémentaux sont plafonnés, tandis que ceux des modèles qui rechargent toutes les données augmentent proportionnellement avec le volume de données. Cela permet de mieux anticiper les coûts de transformation sans mauvaises surprises.
Aujourd’hui, nous allons explorer comment les modèles incrémentaux peuvent résoudre ces problèmes de coûts et de temps d’exécution.
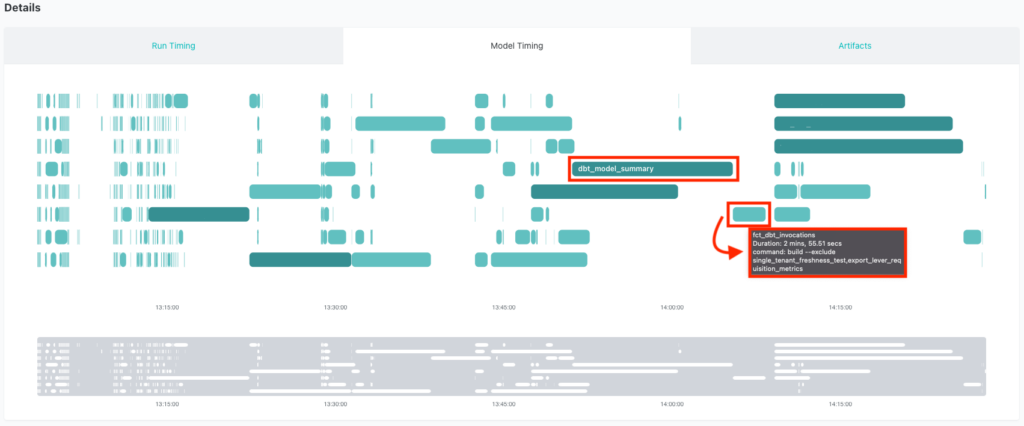
Un bottleneck qui peut potentiellement être résolu grâce à la mise en place d'un modèle incrémental
Matérialisations
Avec une matérialisation de type table, chaque exécution de votre modèle effectue un full refresh de votre table. Cela signifie que la table existante est supprimée (DROP) puis recréée avec l’ensemble des données transformées.
Matérialisation table
Avec une matérialisation de type table, chaque exécution de votre modèle effectue un full refresh de votre table. Cela signifie que la table existante est supprimée (DROP) puis recréée avec l’ensemble des données transformées.
{{
config(
materialized='table'
)
}}
select * from {{ source('my_schema', 'my_table') }}
Matérialisation incremental
La matérialisation incremental, quant à elle, ajoute uniquement les nouvelles données ou celles qui ont changé à la table existante. Cela permet de conserver l’historique des données tout en minimisant le temps de traitement et les ressources utilisées.
{{
config(
materialized='incremental'
)
}}
with new_data as (
select *
from {{ source('my_schema', 'my_table') }}
where updated_at > (select max(updated_at) from {{ this }})
)
select * from new_data
Dans ce modèle, les nouvelles données sont ajoutées à la table existante. Nous utilisons la variable {{ this }} pour faire référence à la table actuelle, et nous récupérons la dernière date de mise à jour pour ne sélectionner que les données mises à jour après la dernière exécution.
Ceci est le fonctionnement de base, mais il y a peu de cas où l’on se limite à ce mode de fonctionnement. Par exemple, lors de la première exécution, la table n’existe pas encore, ce qui entraîne un comportement particulier.
L’utilisation de la macro Jinja is_incremental dans nos modèles dbt permet de gérer ce cas de première exécution. Comme la table n’existe pas encore, dbt ne lancera pas ce modèle de façon incrémentale. Cette condition nous permet donc de spécifier ce qu’il faut faire selon que nous sommes en mode incrémental ou non.
{{
config(
materialized='incremental',
)
}}
with new_data as (
select * from {{ source('my_schema', 'my_table') }}
{% if is_incremental() %}
where updated_at > (select max(updated_at) from {{ this }})
{% endif %}
)
select * from new_data
Il peut arriver que vous ayez besoin de recharger l’intégralité de la table plutôt que d’exécuter le modèle en mode incrémental. Pour ce faire, vous pouvez spécifier le flag full_refresh lors de l’exécution du modèle. Cela permet de forcer un rafraîchissement complet de la table lors de l’exécution, même si la matérialisation incremental est utilisée. Cela peut être utile pour des nettoyages périodiques ou pour gérer des changements majeurs dans les données.
Comme pour la première exécution d’un modèle incrémental, vous devez utiliser la condition is_incremental pour définir ce qu’il faut faire dans le cadre d’un full refresh.
dbt run --full-refresh --select my_model
Paramètres
Avec ce que je viens de présenter, vous pouvez déjà couvrir de nombreux cas d’utilisation, mais il existe différents paramètres qui offrent encore plus de possibilités. Il est crucial de bien comprendre leur fonctionnement car ils peuvent rapidement devenir une source d’erreurs.
unique_key
Par défaut, un modèle incrémental insère simplement les nouvelles données dans la table. Cependant, dans certains cas, il peut être préférable de mettre à jour une donnée déjà existante. La configuration unique_key est alors utile. Lorsqu’une ligne avec une unique_key existante est insérée, dbt met à jour cette ligne plutôt que d’ajouter une nouvelle entrée.
La unique_key peut être un champ unique ou un ensemble de champs.
{{
config(
materialized='incremental',
unique_key='id' // ou ['id', 'date_key']
)
}}
on_schema_change
Il arrive que le schéma du modèle change, par exemple si vous décidez de renommer un champ. Dans certains cas, ce changement de schéma peut être subi, par exemple si une colonne change de type dans un modèle en amont et que ce type se propage à votre modèle incrémental.
Le paramètre on_schema_change définit la manière dont dbt doit réagir dans cette situation. Ce paramètre peut prendre plusieurs valeurs :
- ignore : Si vous ajoutez une colonne à votre modèle incrémental et exécutez un
dbt run, cette colonne n’apparaîtra pas dans votre table cible. - fail : Déclenche une erreur lorsque les schémas source et cible divergent.
- append_new_columns : Ajoute de nouvelles colonnes à la table existante. Notez que ce paramètre ne supprime pas les colonnes de la table existante qui ne sont pas présentes dans les nouvelles données.
- sync_all_columns : Ajoute toutes les nouvelles colonnes à la table existante et supprime celles qui sont désormais absentes. Cela inclut les modifications des types de données.
{{
config(
materialized='incremental',
on_schema_change='sync_all_columns'
)
}}
Attention, quelle que soit la méthode choisie, cela ne mettra pas à jour les données précédentes au moment du changement de schéma. Par exemple, si vous renommez une colonne et choisissez la méthode sync_all_columns, l’ancienne colonne sera supprimée et la nouvelle créée. Cette nouvelle colonne ne contiendra donc pas de données pour les lignes déjà présentes dans la table avant l’opération.
Si vous souhaitez alimenter les anciennes lignes, vous devrez effectuer un full refresh ou les mettre à jour manuellement. C’est ce genre de subtilité qui montre à quel point il est important de bien comprendre ces paramètres pour éviter les erreurs.
incremental_strategy
Un autre paramètre utile pour optimiser encore davantage vos modèles incrémentaux est incremental_strategy. Il vous permet de définir le mécanisme de mise à jour des lignes où la unique_key est déjà présente. Comme ce paramètre dépend énormément du data warehouse que vous utilisez, je ne vais pas m’étendre sur le sujet ici, mais je vous encourage à consulter la documentation spécifique à votre environnement pour en savoir plus.
Tips et conseils
Avec les différentes informations fournies, vous disposez d’un ensemble d’options assez complet. En combinant ces paramètres et en réfléchissant bien à vos requêtes, il est possible d’aborder des optimisations de modèles assez complexes. Je vais vous quitter avec des derniers conseils concernant ce sujet des modèles incrémentaux :
- Munissez-vous d’une solution de Data Observability : que vous optiez pour un outil du marché ou un tableau de bord que vous construisez vous-même, il est crucial de pouvoir identifier rapidement les modèles critiques qui nécessitent une attention particulière. Ce type d’outil offre de nombreux autres avantages, mais avant de se lancer dans l’incrémentalisation d’une table, il est essentiel de pouvoir déterminer quels modèles méritent le temps et les efforts que vous allez y consacrer.
- Inspectez les artifacts : À chaque exécution de vos modèles, dbt génère des fichiers dans le dossier target. Dans le sous-dossier run, vous trouverez toutes les requêtes exécutées. Cela vous permet de voir comment vos modèles sont transformés en fonction de vos différents paramètres, et de rapidement détecter si quelque chose cloche dans la requête générée (souvent en raison d’une mauvaise compréhension d’un paramètre).
- Mettez en place des tests d’anomalies : Comme nous l’avons vu, des erreurs peuvent survenir dans nos modèles incrémentaux (changement de schéma non prévu, colonne mal alimentée, mauvaise construction de la requête, etc.). Des tests d’anomalies peuvent vous alerter en cas de volume anormalement bas de nouvelles données par rapport aux jours précédents, ou lors d’un changement de type de données. Le package dbt-elementary peut répondre à ce besoin. Je prépare un article détaillé sur le sujet.
- Planifiez des full refresh périodiques : Même si les exécutions incrémentales sont puissantes, il peut être judicieux de planifier des full refresh périodiques, par exemple une fois par semaine, pour vous assurer que votre table reste cohérente et pour nettoyer les éventuelles anomalies accumulées.
En appliquant ces bonnes pratiques, vous serez en mesure de créer des pipelines de données robustes et performants avec dbt. Pour plus d’informations et de conseils sur l’optimisation des pipelines de données, n’hésitez pas à consulter mes autres articles ou à me contacter directement !