
Dans les différentes entreprises où je suis intervenu, j’ai pu constater que les cordonniers sont souvent les plus mal chaussés… En effet, j’ai travaillé avec des équipes capables de concevoir des dashboards ultra-complets et efficaces pour les équipes métiers, mais qui étaient incapables de dire quelles transformations avaient ralenti le run de la veille.
J’ai rarement vu un dashboard de suivi d’exécution des modèles dbt. C’est pourtant ce que j’ai été amené à réaliser pour Brut. : un tableau de bord permettant de suivre l’exécution des modèles, le résultat des tests, les anomalies détectées dans les données, etc. L’objectif est d’identifier rapidement les modèles problématiques et de corriger les erreurs au plus vite.
Pour cela, la base de mon travail a été le plugin dbt_artifacts, que j’avais envie de vous présenter aujourd’hui.
Les artifacts en base de données
Avant d’aborder ce package en détail, il est important de comprendre ce que sont les artifacts dans dbt. Il s’agit des métadonnées générées lors des exécutions des différents jobs. À chaque run, plusieurs fichiers JSON sont créés, contenant une multitude d’informations sur la dernière exécution, telles que :
- Le détail des modèles exécutés
- Les résultats des exécutions
- Les résultats des tests
- Les informations sur les sources
- etc.
Ces fichiers sont utilisés, par exemple, dans la documentation dbt, qui y puise les informations nécessaires.
Toutes ces données sont précieuses pour construire un dashboard de suivi des performances des modèles. On pourrait envisager de connecter directement notre outil de visualisation à ces fichiers JSON, mais ce n’est pas un format très pratique. De plus, ces fichiers ne contiennent que les informations du dernier run, sans aucune historisation.
C’est là qu’intervient le package dbt_artifacts, qui permet de stocker ces fichiers JSON en base de données à la fin de chaque exécution.
À retenir : Le package dbt_artifacts nous permet de stocker et historiser toutes les metadata sur les différents objets dbt et toutes les informations sur les différentes exécutions.
Installation de dbt_artifacts
L’installation de ce package est très simple. Il suffit de l’ajouter au fichier packages.yml. Pour obtenir la dernière version, vous pouvez consulter ce lien : dbt_artifacts sur dbt Hub.
Une fois ajouté, il faut exécuter la commande suivante pour l’installer :
dbt deps
Après installation, dbt_artifacts crée plusieurs nouvelles tables et les alimente à chaque exécution :
dim_dbt__current_models: Contient des informations sur les modèles et leur dernière exécution réussiedim_dbt__exposures: Contient des données sur les exposuresdim_dbt__models: Contient des informations détaillées sur les modèlesdim_dbt__seeds: Contient des informations sur les seedsdim_dbt__snapshots: Contient des informations sur les snapshotsdim_dbt__sources: Contient des informations sur les sourcesdim_dbt__tests: Contient des informations sur les testsfct_dbt__invocations: Historise les différentes exécutionsfct_dbt__model_executions: Stocke les détails d’exécution des modèlesfct_dbt__seed_executions: Stocke les détails d’exécution des seedsfct_dbt__snapshot_executions: Stocke les détails d’exécution des snapshotsfct_dbt__test_executions: Stocke les résultats d’exécution des tests
Si vous voulez plus de détail sur ces tables, je vous invite à aller consulter la page dbt Docs de ce package.
À retenir : Grâce à ces tables, il devient possible de connecter un outil de visualisation et d’exploiter ces données pour mieux comprendre les performances des modèles.
Enrichissement des données
Je trouve ces tables très utiles, mais il manque certaines informations essentielles pour mon dashboard, notamment un flag dans la table fct_dbt__model_executions indiquant s’il s’agit du dernier run.
De plus, le modèle de données n’est pas toujours optimal :
- Les flags sont stockés dans des arrays dans les tables de dimension, ce qui les rend difficilement exploitables
- Les dépendances entre les nœuds sont compliquées à manipuler
Afin de remédier à cela, lorsque je travaille pour mes clients, je mets en place des modèles dbt spécifiques au monitoring. Ce qui me permet de rajouter toutes les informations dont j’ai besoin, de croiser avec d’autres sources de données et de restructurer les tables afin d’être plus agréables à exploiter.
Mais pour simplifier cet article, je vais juste rajouter quelques informations grâce à une requête SQL que j’utilise directement dans Tableau :
WITH last_invocation AS (
SELECT DISTINCT
FIRST_VALUE(command_invocation_id) OVER (ORDER BY run_started_at DESC) AS last_invocation_id
FROM `dbt_prod.fct_dbt__invocations`
WHERE dbt_command = 'build'
)
SELECT
me.*,
CASE
WHEN last_invocation.last_invocation_id IS NULL THEN FALSE
ELSE TRUE
END AS is_last_invocation,
bytes_processed / POW(10, 9) AS gb_processed,
(bytes_processed / POW(10, 9)) * 0.02 AS estimated_cost_usd
FROM dbt_prod.fct_dbt__model_executions me
LEFT JOIN last_invocation ON last_invocation.last_invocation_id = me.command_invocation_id
Dans cette requête, j’ajoute également une estimation des coûts BigQuery, car c’est une métrique que je souhaite suivre. Bien qu’elle soit corrélée au nombre de bytes traités, je trouve intéressant d’avoir directement une estimation en USD.
À retenir : dbt_artifacts nous met à disposition différentes tables qu'il est possible d'enrechir de nombreuses autres informations.
Un premier dashboard de monitoring
Grâce à cette requête et aux tables générées par dbt_artifacts, il est possible de construire un premier dashboard de suivi dans Tableau. Il est encore très basique, mais il me permet déjà de :
- Obtenir un résumé clair de la dernière exécution
- Explorer les différents modèles pour identifier ceux qu’il est nécessaire d’optimiser ou de corriger.
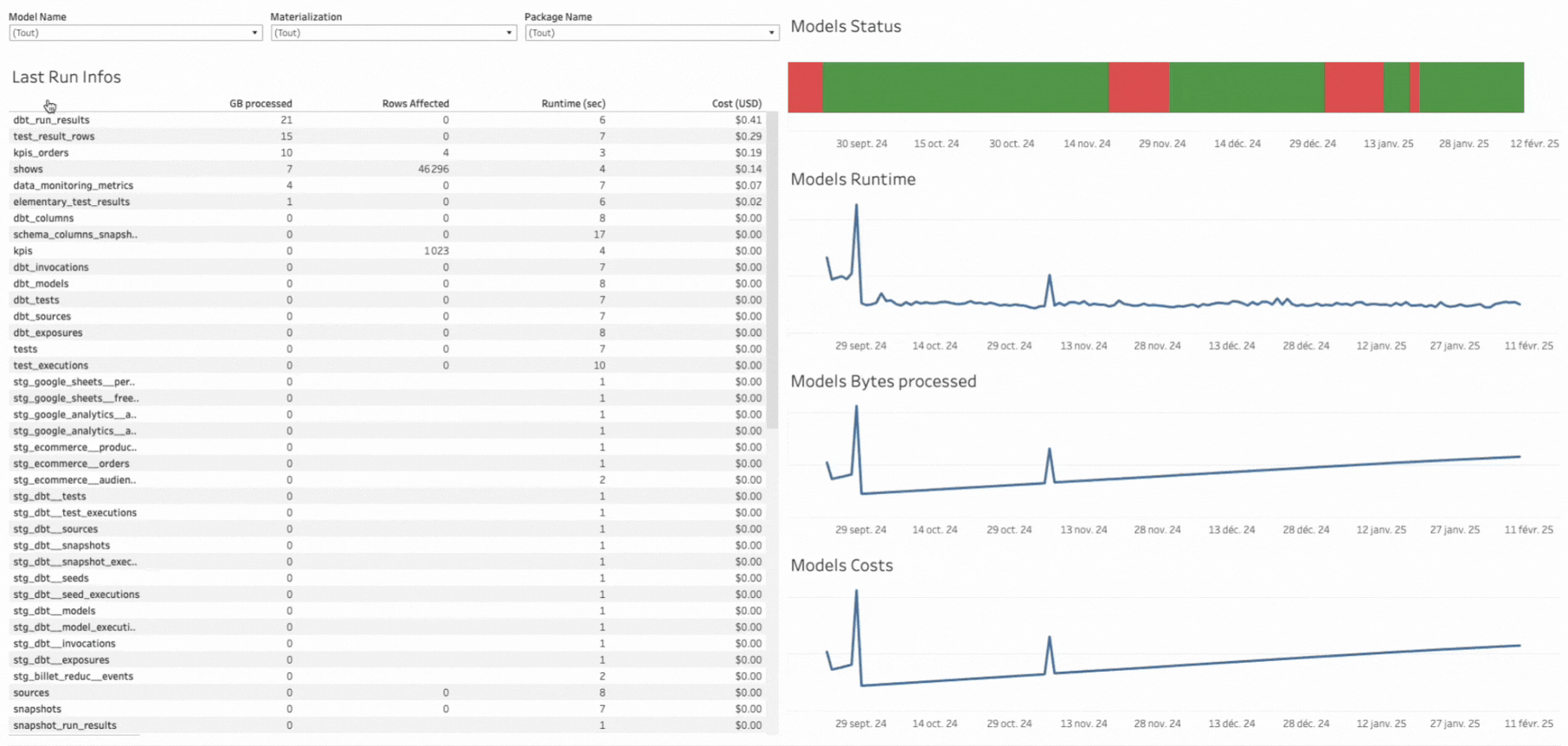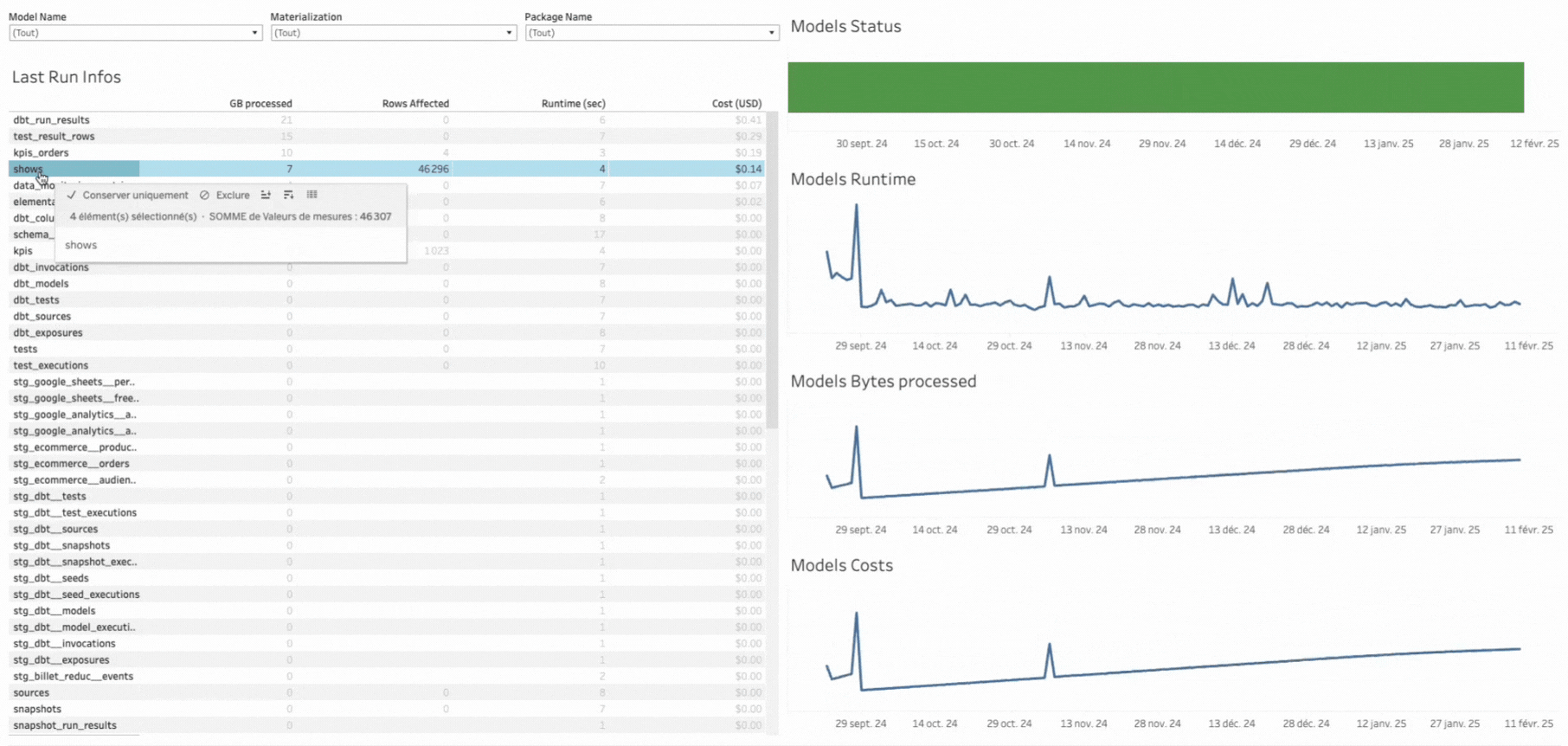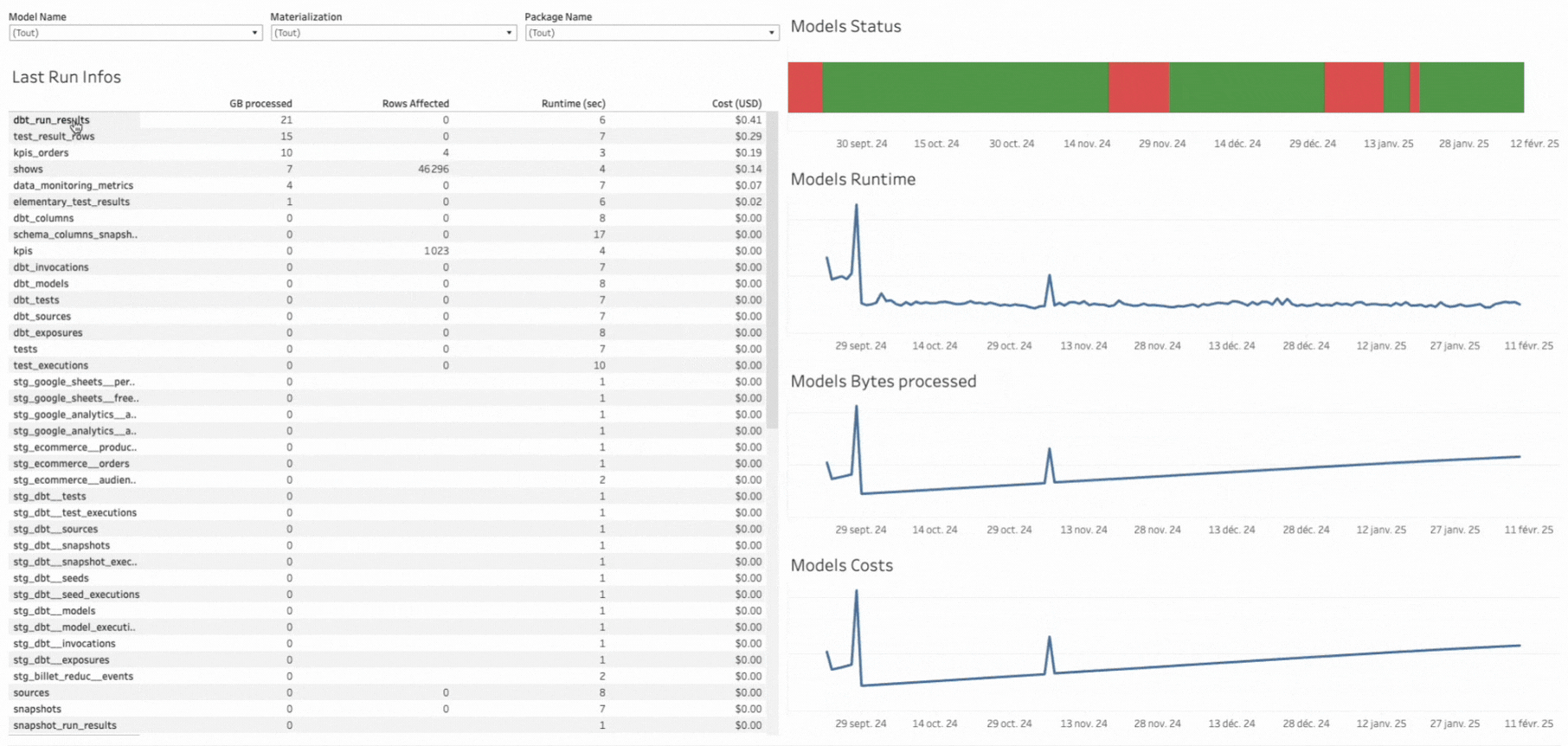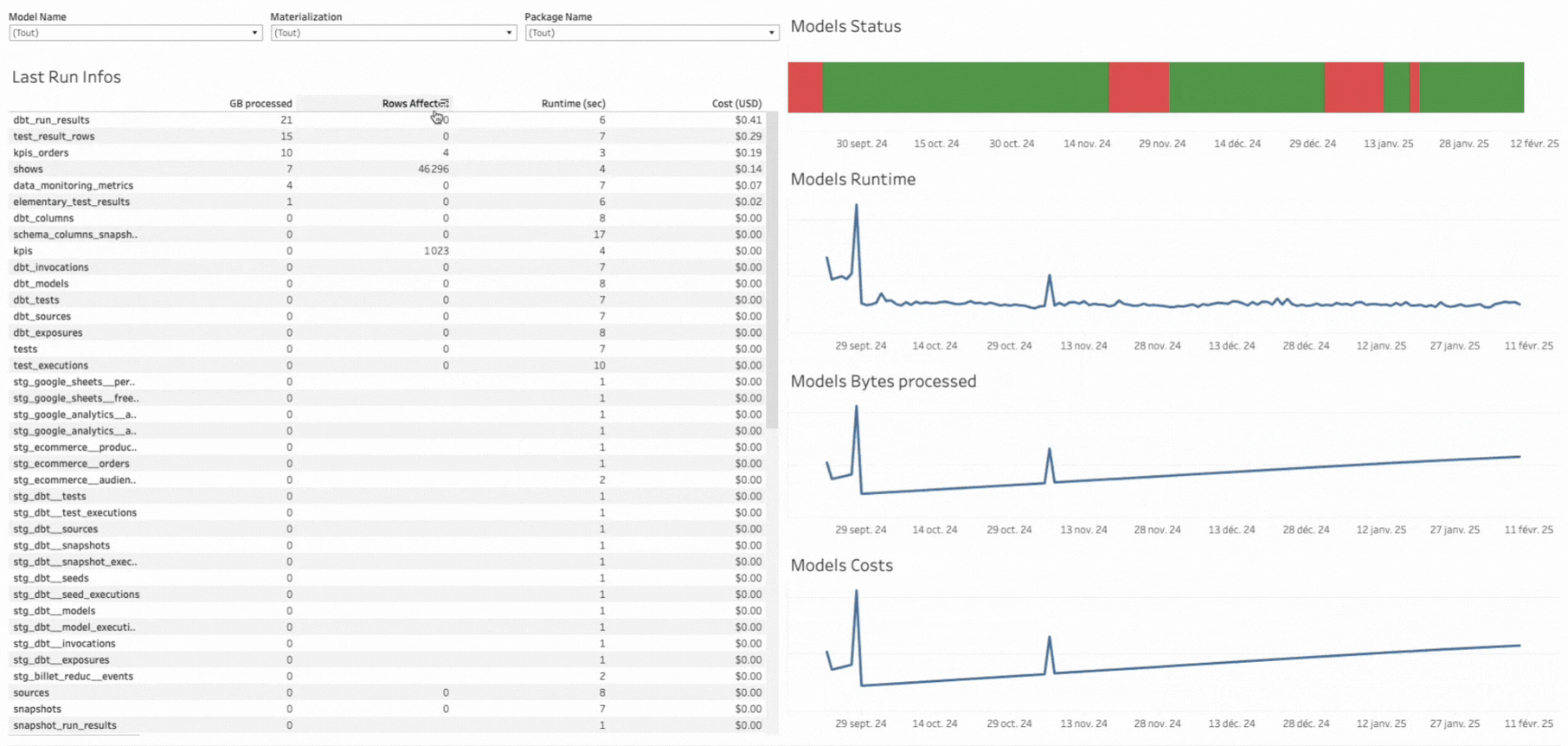
Bien sûr, il s’agit d’une V0, et il est possible d’y ajouter beaucoup d’autres informations, comme :
- Les résultats des tests
- Un filtre par exposure pour analyser le coût de création d’un dashboard
- L’affichage de la freshness des sources
- La détection des anomalies
- etc.
J’ai d’autres métriques que j’aime ajouter à mes dashboards de monitoring. Surtout dans l’objectif de donner le maximum d’informations au développeur afin de faciliter l’optimisation des modèles, mais je garde encore un peu de suspense pour les prochains articles.
Dites-moi si ce sujet vous intéresse, je vous montrerais comment j’optimise cette première version du dashboard afin de monitorer plus efficacement ses modèles et faciliter leur optimisation.