
Dans les Modern Data Stacks, une brique essentielle est le chargement des données sources : ce qu’on appelle un ELT (Extract, Load, Transform). Sur ce blog, nous avons déjà beaucoup parlé de Fivetran et Airbyte, deux solutions cloud clé en main qui facilitent grandement cette phase.
Mais dans certains cas, on a envie d’avoir davantage de contrôle sur cette étape critique de la pipeline. C’est précisément ce que dltHub (ou dlt) permet, et nous allons voir pourquoi cela peut être intéressant.
Les limites des ELT cloud
Fivetran et Airbyte (qui est l’alternative open source à Fivetran) ont de nombreux avantages. Leur force principale réside dans :
- Une prise en main rapide : en quelques clics, il est très simple de mettre en place ses premiers connecteurs, de gérer leurs exécutions et de commencer à charger ses données sources dans son datawarehouse.
- La disponibilité immédiate de centaines de connecteurs pour charger vos données depuis de nombreuses sources et vers les destinations les plus courantes.
Mais j’y vois plusieurs limites importantes :
- L’ajout de nouveaux connecteurs
Même si Fivetran et Airbyte proposent un large catalogue, dès que l’on souhaite récupérer des données d’une source non répertoriée, cela peut vite devenir compliqué.
- Chez Fivetran, il faut attendre qu’ils développent le connecteur ou le développer soi-même via leur SDK.
- Chez Airbyte, il est possible de le coder via le Connector Builder, mais cela reste assez lourd.
- La personnalisation Dès qu’on sort des cas simples ou qu’on souhaite modifier une étape de la pipeline, Fivetran et Airbyte deviennent limitants. On reste contraint par les options disponibles, ce qui peut bloquer certains besoins spécifiques (ex. authentification particulière, transformations custom).
- La gestion des erreurs
- Sur Fivetran, en cas d’erreur, il faut souvent ouvrir un ticket et attendre la correction côté éditeur. Sur les connecteurs les plus populaires, cela se règle vite, mais sur des sources plus “niche”, la résolution peut prendre du temps.
- Sur Airbyte, il faut attendre une correction de la communauté (open source oblige) ou mettre les mains dans le code soi-même, ce qui peut être chronophage.
- Le coût
- Airbyte est open source, mais nécessite des ressources techniques pour le déployer et le maintenir.
- Fivetran est très cher, avec une facturation au volume (MAR – Monthly Active Rows). Dès que les volumes explosent, l’addition devient salée.
Coder son ELT en Python : une fausse bonne idée ?
Une alternative pour pallier ces problèmes consiste à coder soi-même toute la partie extraction/chargement en Python.
J’ai vu beaucoup d’entreprises se lancer dans ce type de projet. Cela peut paraître simple de prime abord. Mais si l’on prend un peu de recul, il s’agit d’un projet assez complexe : coder son ELT from scratch pose de nombreux problèmes :
- Temps de développement et de maintenance : développer ses connecteurs, en fonction de leur complexité, peut demander énormément de temps car cela implique de nombreuses opérations (extraction, normalisation, gestion des erreurs, gestion des types, etc.).
- Robustesse : pour une pipeline “bien faite”, il faut gérer les tests, la documentation, les logs, la reprise sur erreur, etc. Tout cela représente un surcroît de travail et donc de temps de développement.
- Performance : concevoir une pipeline performante demande des compétences techniques parfois difficiles à trouver (parallélisation, traitement par lot, etc.).
- Architecture : pour optimiser les points précédents, il est nécessaire de mettre en place une architecture efficace. Là encore, cela exige de solides compétences en interne.
Le principe de dltHub
C’est ici que dlt devient intéressant : c’est une bibliothèque Python open source qui permet d’écrire des pipelines d’extraction de données en quelques lignes de code, tout en intégrant des mécanismes de robustesse et de performance.
Exemple minimal
import dlt
from dlt.sources.rest_api import rest_api_source
source = rest_api_source({
"client": {
"base_url": "https://fakestoreapi.com/",
},
"resources": ["products"]
})
pipeline = dlt.pipeline(
pipeline_name="rest_api_example",
destination="bigquery",
dataset_name="fake_store",
)
load_info = pipeline.run(source)
# print load info and posts table as dataframe
print(load_info)
print(pipeline.dataset().products.df())
En quelques lignes, on a :
- défini une source (une API REST),
- choisi une destination (BigQuery),
- exécuté une pipeline complet avec extraction, normalisation et chargement.
Personnalisation avancée
À cette pipeline minimaliste, on peut ajouter de nombreuses personnalisations, difficiles à développer soi-même :
- Chargement incrémental des données.
- Gestion des schémas avec règles en cas de mismatch.
- Logging complet des étapes.
- Transformations intermédiaires en Python avant le chargement.
- Parallélisation et optimisation des performances.
- etc.
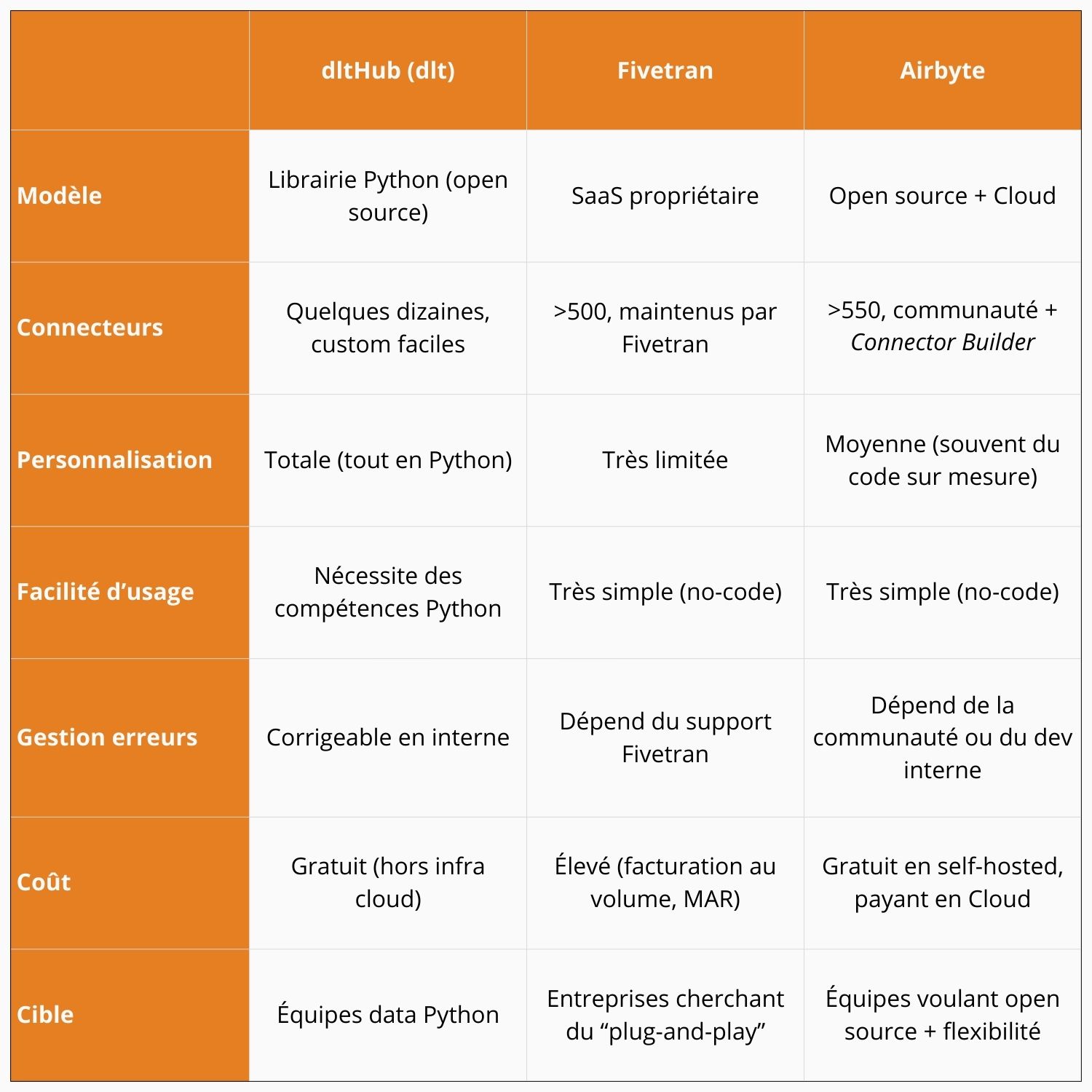
Tableau comparatif : dlt vs Fivetran vs Airbyte
Si l’on reprend les inconvénients de Fivetran et Airbyte, on voit que dlt résout la plupart des problèmes identifiés :
- L’ajout de nouveaux connecteurs : créer un connecteur en Python avec dlt est simple et rapide, grâce aux outils intégrés.
- La personnalisation : il est facile de modifier un connecteur ou d’ajouter des étapes dans le traitement des données.
- La gestion des erreurs : comme tout est en Python, elles peuvent être corrigées directement en interne.
- Le coût : dlt est un outil open source, et donc “gratuit”.
Cependant, il faut nuancer ce dernier point :
- Il est nécessaire d’avoir une équipe data plus conséquente que lorsqu’on utilise Fivetran ou Airbyte, car il faut plus de ressources pour développer, maintenir et faire évoluer cette partie de la pipeline.
- Il faut héberger son instance de dlt et donc payer les coûts d’infrastructure.
- Il faut des ressources en interne pour maintenir l’infrastructure.
En résumé, deux philosophies s’opposent :
- Fivetran/Airbyte : rapidité de mise en place, simplicité pour l’utilisateur métier, mais faible personnalisation et dépendance à l’éditeur.
- dlt : plus de travail côté Data Engineers, mais une liberté totale pour adapter la pipeline aux besoins réels.
À qui s’adresse dlt ?
- Aux équipes data à l’aise avec Python, qui veulent construire des pipelines robustes et personnalisés.
- Aux startups qui veulent éviter les coûts de Fivetran et garder la flexibilité du code.
- Aux Data Engineers qui cherchent un outil moderne, performant et léger à maintenir.
Là où Fivetran réduit vos besoins en Data Engineers (au prix fort), dlt mise sur vos compétences Python et vous rend la liberté.