
Sur ce blog, je vous parle souvent d’outils pour bâtir une stack data. Pourtant, la méthode compte davantage : les outils changent, mais la façon de structurer les données reste.
Au cœur de cette méthode, une étape concentre l’essentiel : la modélisation.
Dans cet article, je vous explique pourquoi elle est déterminante et je vous partage ma méthode, éprouvée au fil de nombreux projets de mise en place de stack data.
Quand la modélisation est mauvaise : conséquences concrètes
La modélisation est fréquemment sous-estimée : elle prend du temps et semble « évidente ». Et dans ce genre de projet, on entend vite « on se débrouillera ». Et on se retrouve rapidement avec des data analysts qui essaient de faire parler comme ils peuvent les data en bidouillant dans l’outil de visualisation… et cela rend la data très fragile.
Voici les problèmes qui finissent par apparaître :
1. Changements et corrections coûteux
Prendre le temps d’une bonne modélisation évite de tout reprendre par la suite (même s’il y aura toujours des ajustements).
Revoir le modèle en cours de route oblige à toucher aux pipelines, dashboards, tests, documentation, etc. C’est très coûteux.
2. Décisions métiers peu fiables
Une modélisation sérieuse commence par la définition et la validation des indicateurs.
Résultat : des chiffres fiables et, derrière, des décisions solides.
3. Pas de scalabilité ni d’évolutivité
Un bon modèle accueille les évolutions (nouveaux KPIs, nouvelles vues, nouvelles sources).
Un modèle bâclé ne s’adapte pas : vous finissez par refaire, tordre l’existant ou dupliquer des modèles. C’est coûteux et cela fragilise la fiabilité de la stack.
4. Développement ralenti
Un modèle explicite (grains, clés, définitions KPI) donne une direction claire qu’il est ensuite plus simple de mettre en place dans les pipelines car on sait où l’on va.
Sans cible, on avance « au feeling », on multiplie les allers-retours et on perd du temps.
5. Requêtes chères et/ou très lentes
La modélisation doit intégrer la performance. Un mauvais modèle ralentit l’analyse (viz ou requêtes ad hoc) et frustre les utilisateurs.
Sur les entrepôts facturés à la complexité ou au volume scanné, un modèle pas adapté fait exploser les coûts.
Ma méthode pour réussir la modélisation
Depuis 8 ans, je mets en place des stacks data dans des entreprises de tailles variées. Cette expérience m’a permis d’affiner une méthode qui fonctionne.
1. Cadrage métier
Je rencontre vos équipes afin de m’imprégner de votre fonctionnement actuel pour identifier :
- Problématiques et frustrations
- Outils utilisés et modes d’usage
- Besoins futurs
- Indicateurs clés
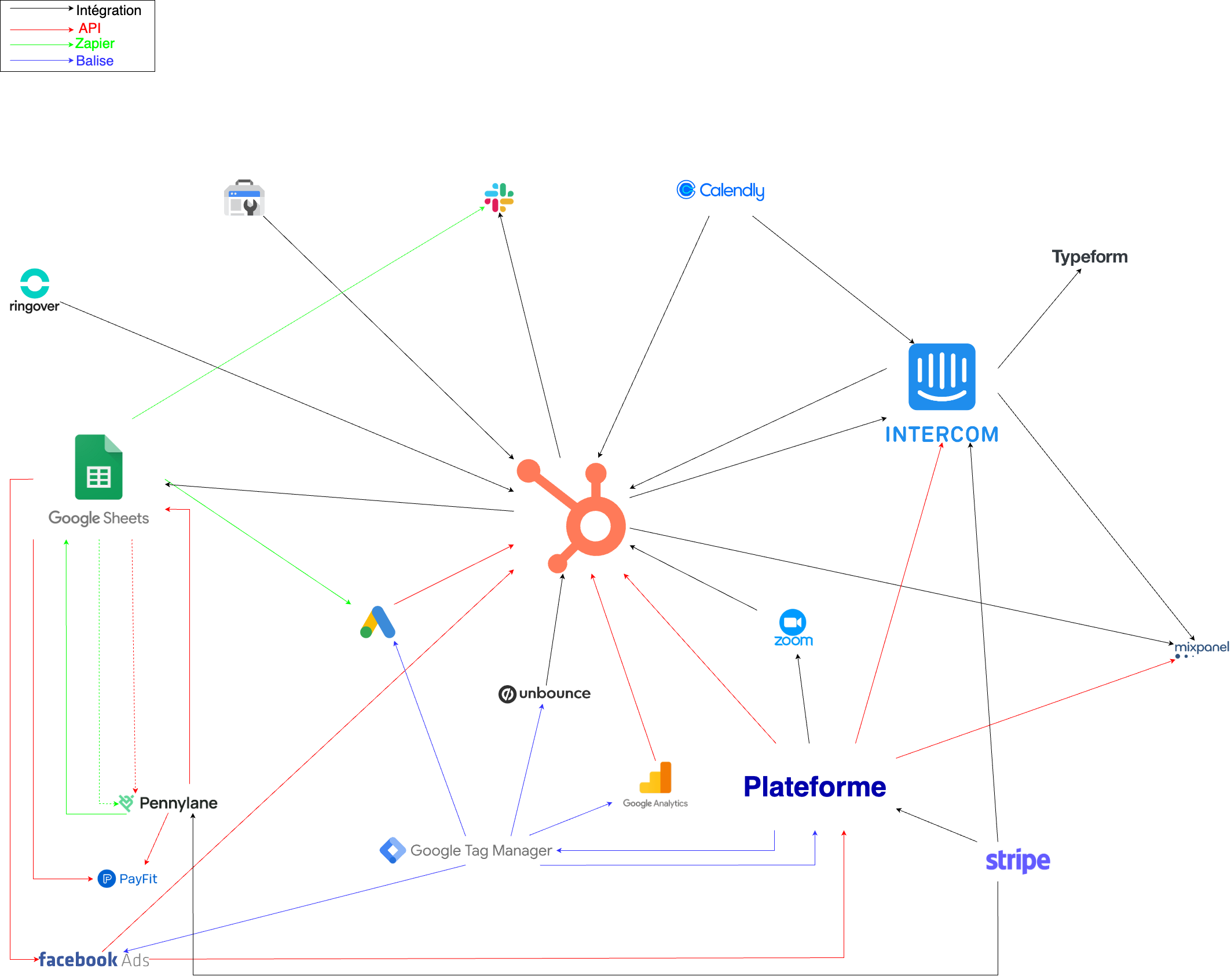
2. Cartographie des sources de données
Je cartographie les sources accessibles (outils, bases, fichiers).
Objectifs : visualiser tous les flux à mettre en place et anticiper quels KPIs seront calculables et comment.
Livrable : une cartographie que je vous partage et que vous validez afin de m’assurer votre façon de travailler actuelle.
3. Définition des indicateurs attendus
Avec les besoins clarifiés et les sources listées, je cadre les KPIs : définition métier, formules de calcul, règles d’inclusion/exclusion, périodes, etc.
Livrable : le référentiel des indicateurs que vous validez afin qu’on soit alignés sur ce qui est attendu. Il me servira aussi à documenter le data warehouse dans la suite du projet.
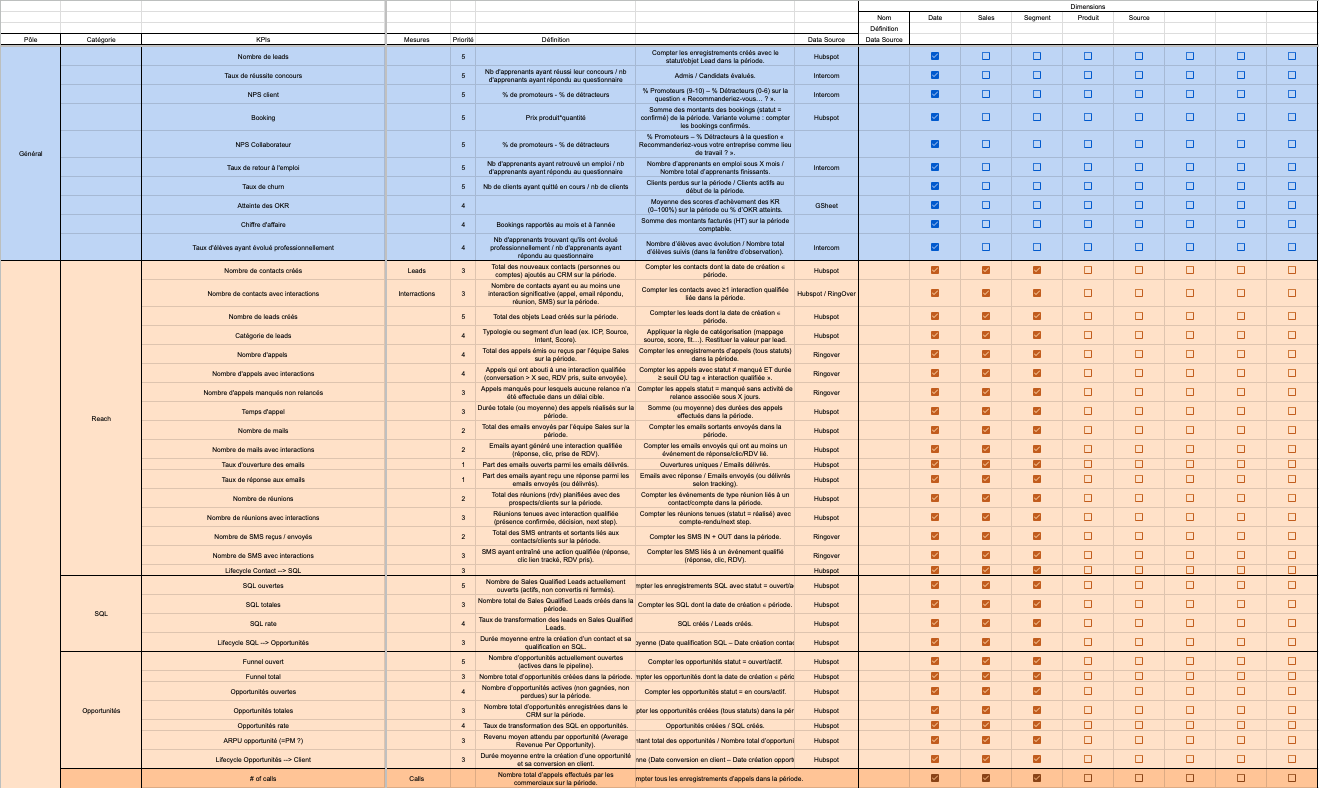
4. Dimensions, mesures et grains
Pour chaque indicateur, je liste les mesures nécessaires et j’explicite le grain attendu.
Question clé : « 1 ligne = ? »
Je recense également les dimensions utiles (temps, produit, client, canal, région…).
5. Choix de la stratégie et schématisation
Plusieurs approches sont possibles : modélisation dimensionnelle, Data Vault, One Big Table, etc.
Chaque stratégie a ses avantages et limites. Tout le travail amont permet de choisir la bonne.
Livrable : un schéma cible (feuille de route) clair, annoté, partagé.
6. Livraison par incréments
Sur les projets conséquents, je priorise un domaine pour une première livraison rapide :
- Vous obtenez de la valeur immédiatement
- On réaligne la vision si nécessaire
- On valide la modélisation avant de déployer à grande échelle
- On rassure sur le temps investi dans la modélisation
Conclusion
La modélisation est trop souvent négligée, parfois même zappée. J’espère vous avoir convaincu de son rôle central et fourni des repères concrets pour l’aborder efficacement.
Si vous souhaitez que j’intervienne pour cadrer, concevoir ou challenger la modélisation de votre stack data, contactez-moi, ça sera un plaisir de vous accompagner sur le sujet.