
La qualité des données est un enjeu crucial dans tout projet de transformation de données. Pour garantir des analyses fiables et une prise de décision éclairée, il est essentiel de mettre en place une stratégie de tests claire et efficace.
Dans un précédent article, je vous présentais comment mettre en place des tests dans dbt. Aujourd’hui, je souhaite partager avec vous ce qui me semble être les principales composantes d’une bonne stratégie de tests, et voir concrètement quels types de tests mettre en place.
Mais avant de plonger dans les détails pratiques, rappelons les éléments qu’une telle stratégie doit garantir.
Quelles sont les dimensions de la Data Quality ?
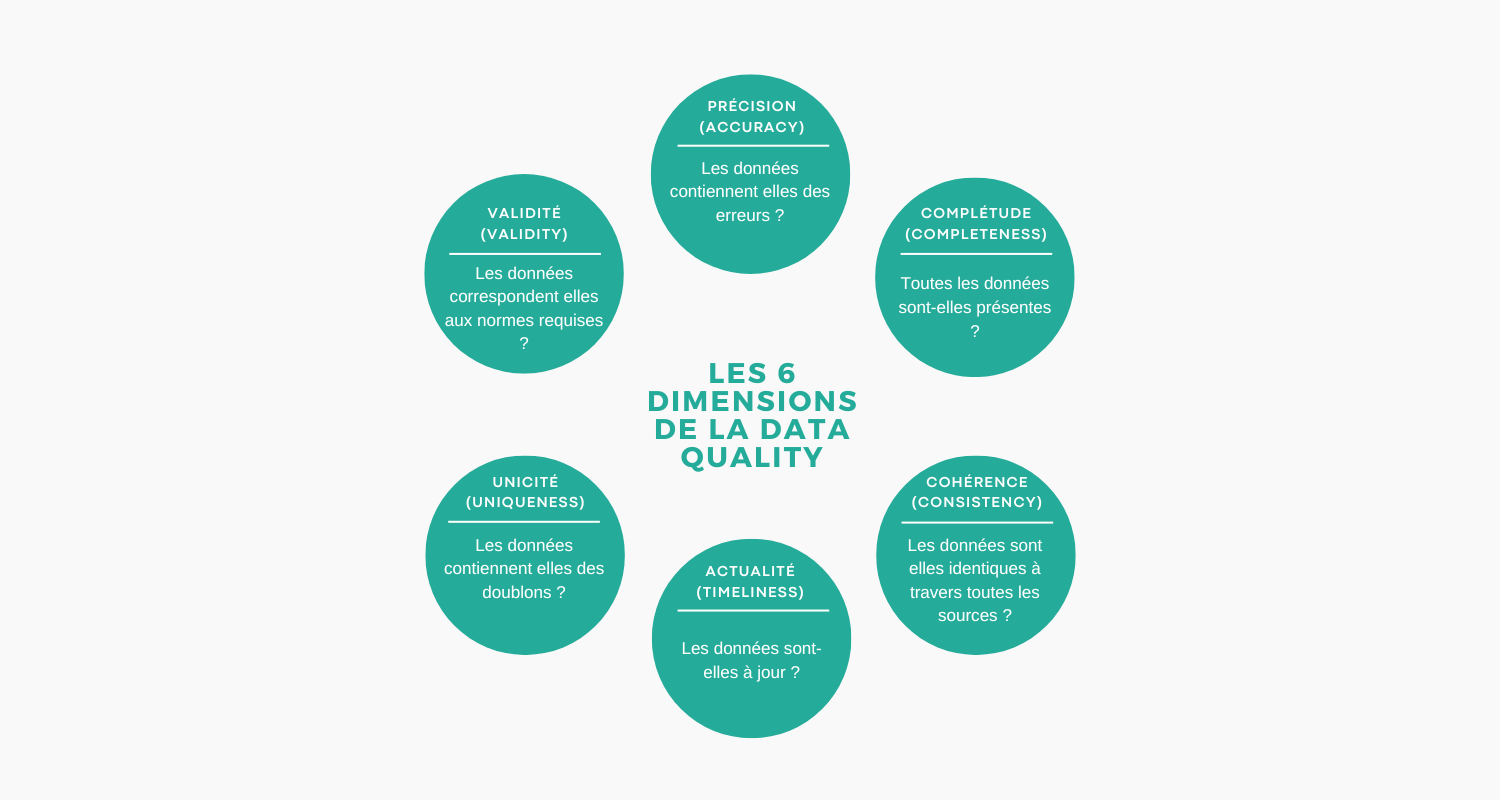
Une bonne stratégie de tests doit s’assurer que les données répondent aux six dimensions fondamentales de la qualité des données :
- Précision (Accuracy) : Les données sont précises et correctes, sans erreurs.
- Complétude (Completeness) : Toutes les données requises sont présentes.
- Cohérence (Consistency) : Les données sont uniformes et logiquement cohérentes entre les différents ensembles de données.
- Actualité (Timeliness) : Les données disponibles sont à jour.
- Unicité (Uniqueness) : Les données ne contiennent pas de doublons.
- Validité (Validity) : Les données sont conformes aux formats, valeurs et normes requis.
Ça, c’est la théorie, mais en pratique, quels tests mettre en place ? En m’appuyant sur ces dimensions, voyons quels tests doivent être implémentés dans un projet dbt.
Les tests à mettre en place dans dbt
Pour garantir les six dimensions mentionnées précédemment, certains tests sont essentiels à mettre en place dans dbt. Je vous les présente selon mon ordre de priorité, basé sur la facilité de mise en œuvre et l’impact sur la qualité des données.
1. Tests de schéma : clés primaires (PK) et clés étrangères (FK)
Ces tests sont les plus simples à mettre en place et, d’expérience, ce sont ceux qui permettent de détecter rapidement des problèmes dans les données.
- Pourquoi ? Détecter des doublons sur une clé primaire ou des références manquantes sur une clé étrangère alerte immédiatement sur des problèmes d’intégrité référentielle ou de duplication.
- Comment ? Dans dbt, il est très simple de mettre en place ce type de test en utilisant les tests intégrés pour les contraintes d’unicité et de relations.
Exemple d’implémentation :
models:
- name: orders
columns:
- name: order_id
tests:
- unique
- not_null
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: id
Dans cet exemple, je vérifie que order_id est unique et non null (clé primaire) et que customer_id existe dans la table customers (clé étrangère).
2. Tests des valeurs non nulles et valeurs acceptées
Une fois assuré que ma table a la bonne structure, je peux tester les données elles-mêmes.
- Pourquoi ? Vérifier que les valeurs ne sont pas nulles et qu’elles appartiennent à un ensemble de valeurs acceptées garantit la validité des données.
- Comment ? En me concentrant sur les champs importants, je peux mettre en place des tests qui alertent rapidement sur des anomalies faciles à identifier.
Exemple d’implémentation :
models:
- name: products
columns:
- name: product_name
tests:
- not_null
- name: category
tests:
- accepted_values:
values: ['Electronics', 'Home', 'Clothing', 'Food']
Ici, je m’assure que product_name n’est pas null et que category contient uniquement des valeurs prédéfinies.
3. Tests de fraîcheur (Freshness) : les données sont-elles bien alimentées à l'intervalle défini ?
Ce type de test permet de détecter rapidement un problème dans l’alimentation des données.
- Pourquoi ? S’assurer que les données sont à jour est crucial pour les analyses qui dépendent de la fraîcheur des informations.
- Comment ? dbt offre des fonctionnalités pour tester la fraîcheur des sources de données, notamment via les tests intégrés ou en utilisant le package
Elementary.
Exemple d’implémentation :
sources:
- name: api_transactions
tables:
- name: transactions
freshness:
warn_after: {count: 12, period: hour}
error_after: {count: 24, period: hour}
Avec ce test, je serai alerté si les données de transactions ne sont pas mises à jour depuis 12 heures (avertissement) ou 24 heures (erreur).
Une solution un peu plus complexe à mettre en place, mais que je trouve plus efficace et qui possède de nombreux avantages, est l’utilisation du package Elementary. Je détaillerai ce point dans un futur article.
4. Tests de cohérence : les données sont-elles cohérentes ?
Afin d’identifier rapidement des erreurs dans mes données, il est également possible de mettre en place des tests qui vont s’assurer que les données sont bien cohérentes entre les différentes sources.
Tests des règles métiers
La première solution est de valider des règles métiers.
- Pourquoi ? Les tests des règles métiers permettent de vérifier que les données respectent les contraintes spécifiques à votre domaine d’activité.
- Comment ? En implémentant des tests personnalisés qui reflètent les règles métiers, ou en utilisant des tests avancés fournis par
dbt-expectationsouElementary.
Exemple d’implémentation avec dbt-expectations :
models:
- name: orders
tests:
- dbt_expectations.expect_column_pair_values_to_be_equal:
column_A: total_amount
column_B: unit_price * quantity
Ce test s’assure que le total_amount correspond bien au produit du unit_price et de la quantity.
Tests de cohérence inter-tables
La seconde option qui s’offre à moi est de comparer une donnée qui doit être identique entre différentes tables.
- Pourquoi ? Les tests de cohérence vérifient l’uniformité des données entre différentes tables ou systèmes.
- Comment ? En comparant les données pour s’assurer qu’il n’y a pas de contradictions, en utilisant des tests personnalisés ou des packages dédiés.
Exemple d’implémentation avec Elementary :
models:
- name: orders
tests:
- elementary.column_values_equality:
compare_model: ref('shippings')
column_pairs:
- column_a: order_status
column_b: shipping_status
join_columns:
- order_id
Ce test vérifie que le statut de la commande est cohérent entre les tables orders et shippings.
5. Tests sur les types de données (Data Types)
Un autre type de test qui est important, mais qui est plus situationnel que les autres, est un check des types de données.
- Pourquoi ? Dans dbt, vu que par défaut nous ne spécifions pas les types de données et que ces types sont déduits des résultats de la requête dans le modèle, ces types peuvent changer d’un instant à l’autre en cas d’erreur dans un modèle qui précède, par exemple.
Voir un type de données qui change (par exemple, un ID qui est censé être un entier devenir un string) peut mettre le doigt sur une erreur dans la chaîne de transformations.
Cela est également très important lorsque la table est utilisée par un outil de visualisation. Le changement de type d’un champ peut casser l’un de vos dashboards. - Comment ? Le package
Elementarypropose un test complètement adapté à ce besoin.
Exemple d’implémentation avec Elementary :
models:
- name: login_events
columns:
- name: loaded_at
data_type: timestamp
- name: event_name
data_type: text
- name: event_id
data_type: integer
tests:
- elementary.schema_changes_from_baseline
6. Tests d'anomalies
Ces tests sont plus complexes à mettre en place, mais ils sont très puissants car ils permettent d’être proactif sur les erreurs qui sont habituellement remontées par les utilisateurs finaux.
Les anomalies peuvent intervenir à plusieurs niveaux :
- Volumes : S’assurer que le volume de données est cohérent.
- Valeurs : Vérifier qu’un champ a des valeurs acceptables comparées au passé.
Pour voir des exemples de tests d’anomalies et en savoir plus sur ce que propose le package Elementary, je vous renvoie vers cet article que j’y avais consacré.
Ces tests deviennent rapidement essentiels sur des jeux de données cruciaux qui sont beaucoup utilisés et sur lesquels les enjeux sont importants.
Conclusion
La mise en place de tests de qualité des données est indispensable pour garantir la fiabilité des analyses et la confiance des utilisateurs finaux. En utilisant dbt et des packages comme dbt-utils, dbt-expectations et Elementary, il est possible d’automatiser ces tests et de les intégrer directement dans votre workflow de développement.
En suivant cette approche, vous pouvez prioriser les tests qui auront le plus grand impact sur la qualité de vos données, tout en construisant progressivement une suite de tests complète couvrant toutes les dimensions de la qualité des données.
N’oubliez pas que la qualité des données n’est pas un état statique, mais un processus continu. Il est donc crucial de réviser et d’adapter régulièrement vos tests pour répondre aux évolutions de vos données et de vos besoins métiers !