
La semaine dernière, nous avons construit la première version d'un dashboard de monitoring des modèles dbt. Si vous ne l'avez pas encore lu, je vous conseille d'y jeter un œil avant de poursuivre la lecture de cet article.
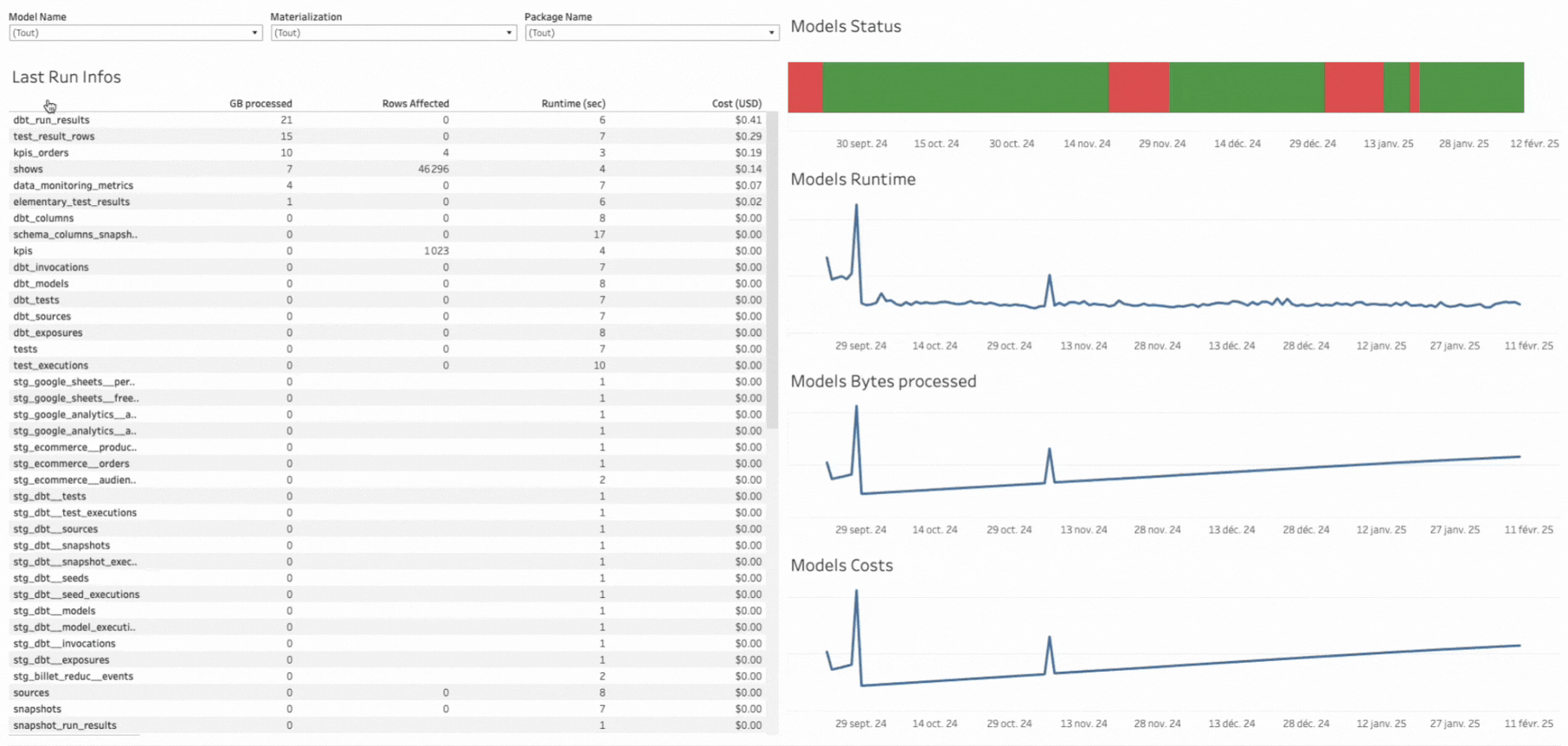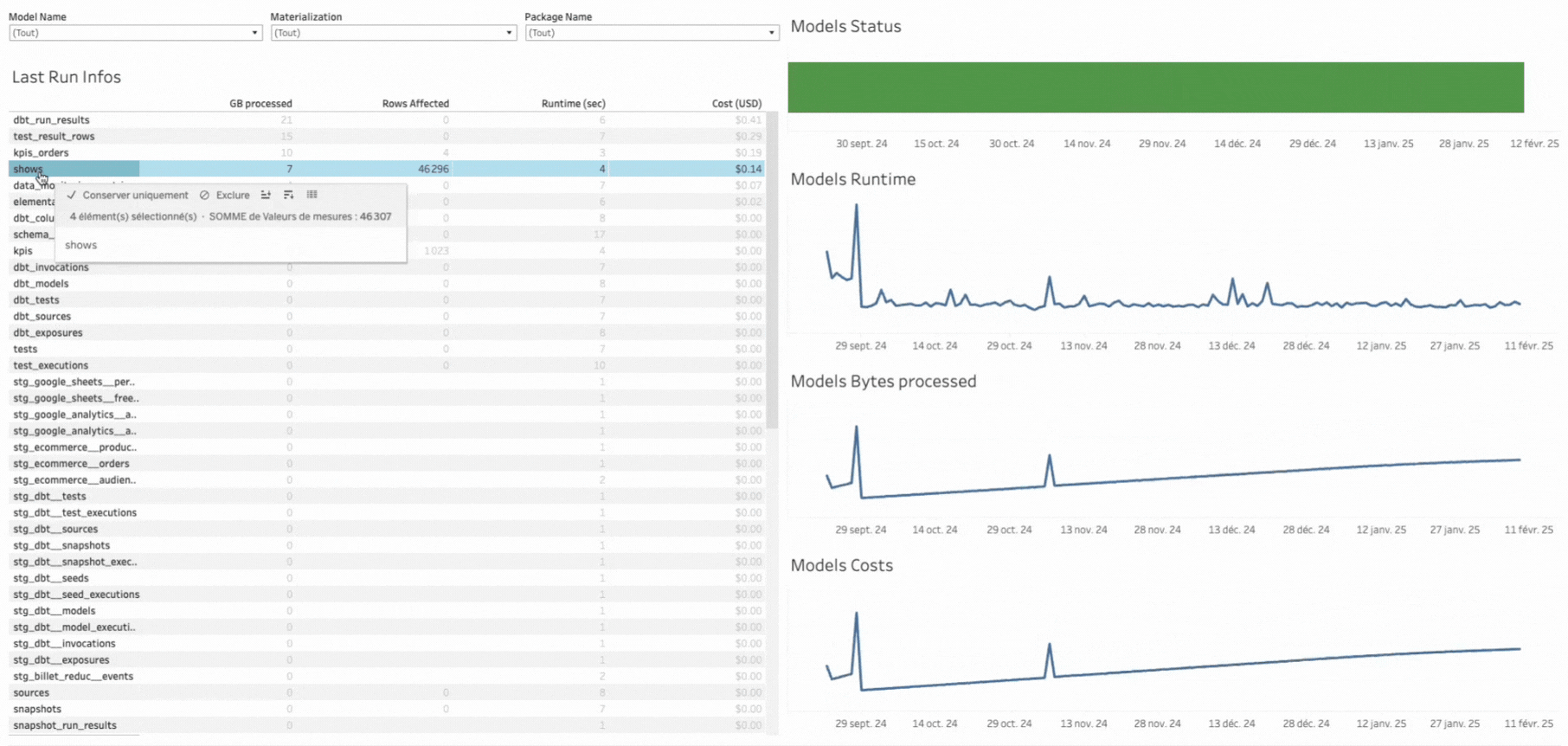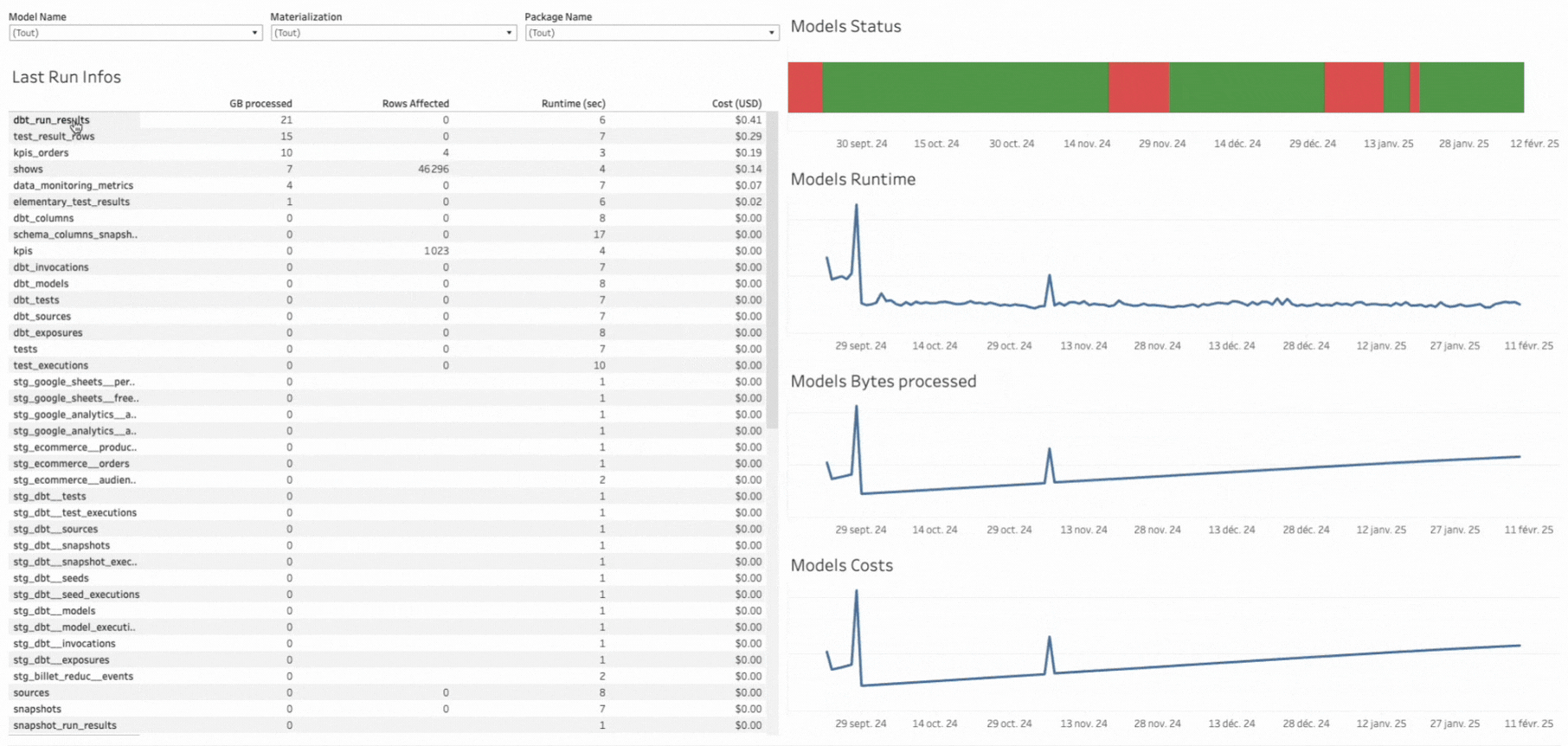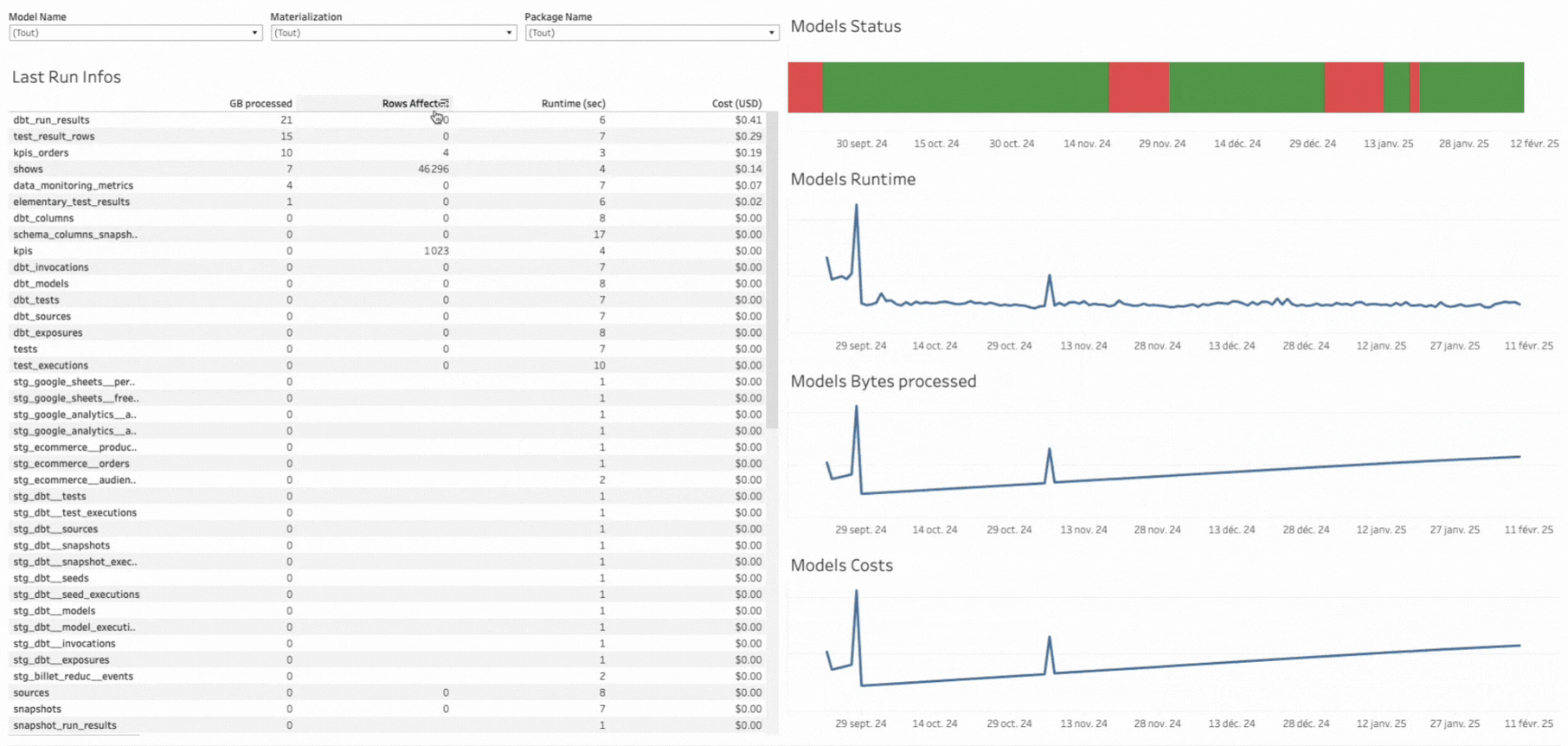
Dans cette première version, nous remontions différentes informations liées à l'exécution des modèles :
- Temps d'exécution
- Statut
- Nombre de lignes traitées
- Materialization
- Nombre de bytes traités
À partir de cette dernière information, nous calculions une estimation du coût d'exécution du modèle. Cependant, dans BigQuery, le coût d'une requête ne se calcule pas à partir de ce champ, mais à partir du nombre de bytes scannés. Cette information n'est malheureusement pas disponible dans les données remontées par le package dbt_artifacts, que nous utilisons pour collecter ces métriques.
Dans cet article, nous allons voir comment enrichir notre dashboard de monitoring afin d'obtenir une estimation beaucoup plus précise des coûts.
Récupérer les données depuis BigQuery
BigQuery met à disposition des vues dans INFORMATION_SCHEMA, permettant de récupérer de nombreuses informations sur un projet BigQuery.
En particulier, la vue INFORMATION_SCHEMA.JOBS contient différentes statistiques sur l'exécution des requêtes, dont un champ clé : total_bytes_billed, qui correspond exactement à l'information utilisée par BigQuery pour calculer le montant facturé.
Pour convertir cette valeur en coût monétaire, il faut se référer à la page de tarification de BigQuery.
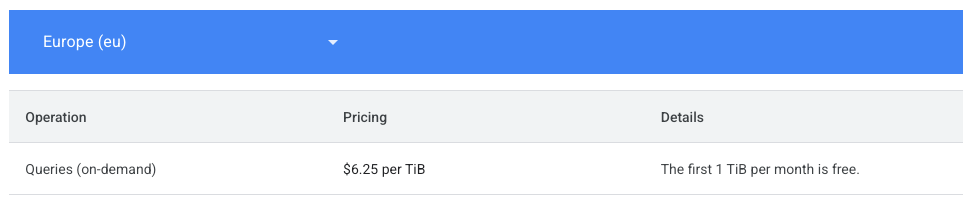
Dans notre cas, nous allons utiliser un coût de 6,25 $ par TiB pour calculer les coûts. Idéalement, cette donnée devrait être stockée dans une table de configuration, mais pour notre exemple, nous allons la coder en dur dans la requête.
La conversion de total_bytes_billed en TiB se fait avec la formule suivante :
total_bytes_billed / POW(2, 40)
À retenir : Pour avoir une estimation fiable des coûts BigQuery, nous utilisons le champ
total_bytes_billedde la vueINFORMATION_SCHEMA.JOBS.
Faire le lien entre les données BigQuery et dbt
Nous avons maintenant d'un côté toutes les informations en provenance de BigQuery, principalement le coût des différents jobs exécutés. Et de l'autre, nous avons toutes les autres données concernant l'exécution de nos modèles dbt (métadonnées des modèles, temps d'exécution, statuts, etc.).
Nous allons maintenant devoir trouver un moyen de faire le lien entre ces deux sources d'information.
Par chance, dans la vue INFORMATION_SCHEMA.JOBS, nous avons le champ query qui contient la requête exécutée par le job. Et dbt rajoute par défaut différentes informations en commentaires de chaque requête qu'il exécute. Ce commentaire est un objet JSON qui contient quelques informations qui vont nous être utiles :
/* {"app": "dbt", "dbt_version": "2025.2.10+645da27", "profile_name": "user", "target_name": "default", "node_id": "model.datengo.stg_ecommerce__audience"} */
...
Nous allons pouvoir extraire le node_id de ce commentaire et en nous basant sur la date d'exécution de la requête par la suite, nous pourrons retrouver l'exécution correspondante dans les données en provenance de dbt_artifacts :
SELECT
job_id,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.app') AS app,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.dbt_version') AS dbt_version,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.profile_name') AS profile_name,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.target_name') AS target_name,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.node_id') AS node_id
FROM `datengo.region-eu.INFORMATION_SCHEMA.JOBS`
Pour information, si vous voulez rajouter des informations dans cet objet JSON, je vous conseille cet article que j'ai trouvé très intéressant.
À retenir : Pour faire le lien entre les données de BigQuery et celles du package
dbt_artifacts, on utilise lenode_idinséré en commentaire de chaque requête exécutée par dbt.
Nous avons maintenant toutes les informations nécessaires pour enrichir notre dashboard !
Enrichir la requête finale
Reprenons la requête de la semaine dernière qui servait à construire le dashboard :
WITH last_invocation AS (
SELECT DISTINCTFIRST_VALUE(command_invocation_id) OVER (ORDER BY run_started_at DESC) AS last_invocation_id
FROM `dbt_prod.fct_dbt__invocations`
WHERE dbt_command = 'build'
)
SELECT
me.*,
CASEWHEN last_invocation.last_invocation_id IS NULL THEN FALSEELSE TRUEEND AS is_last_invocation,
bytes_processed / POW(10, 9) AS gb_processed,
(bytes_processed / POW(10, 9)) * 0.02 AS estimated_cost_usd
FROM dbt_prod.fct_dbt__model_executions me
LEFT JOIN last_invocation ON last_invocation.last_invocation_id = me.command_invocation_id
Nous allons remplacer estimated_cost_usd par notre nouvelle estimation de coût et en profiter pour optimiser certaines parties de la requête :
WITH last_invocation AS (
-- Récupère l'ID de la dernière invocation du dbt buildSELECTFIRST_VALUE(command_invocation_id) OVER (ORDER BY run_started_at DESC) AS last_invocation_id
FROM `dbt_prod.fct_dbt__invocations`
WHERE dbt_command = 'build'
LIMIT 1
),
bq_stats AS (
-- Récupère les statistiques des requêtes BigQuery associées à dbt
SELECT
job_id,
start_time,
end_time,
total_bytes_processed,
total_bytes_billed,
total_slot_ms,
user_email,
query,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.app') AS app,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.dbt_version') AS dbt_version,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.profile_name') AS profile_name,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.target_name') AS target_name,
JSON_VALUE(REGEXP_EXTRACT(query, r'/\* (.*?) \*/'), '$.node_id') AS node_id
FROM `datengo.region-eu.INFORMATION_SCHEMA.JOBS`
),
model_executions AS (
-- Récupère les exécutions de modèles dbt cibléesSELECT
node_id,
model_execution_id,
command_invocation_id,
run_started_at,
was_full_refresh,
thread_id,
status,
compile_started_at,
query_completed_at,
total_node_runtime,
rows_affected,
bytes_processed,
materialization,
schema,
name,
alias,
message,
COALESCE(last_invocation.last_invocation_id IS NOT NULL, FALSE) AS is_last_invocation
FROM dbt_prod.fct_dbt__model_executions
LEFT JOIN last_invocation
ON last_invocation.last_invocation_id = command_invocation_id
),
final_result AS (
-- Jointure des exécutions dbt avec les stats BigQuery et la dernière invocationSELECT
me.model_execution_id,
me.command_invocation_id,
me.run_started_at,
me.was_full_refresh,
me.thread_id,
me.status,
me.compile_started_at,
me.query_completed_at,
me.total_node_runtime,
me.rows_affected,
me.bytes_processed,
me.materialization,
me.schema,
me.name,
me.alias,
me.message,
me.is_last_invocation,
SUM(bq_stats.total_bytes_billed) AS total_bytes_billed,
SUM(bq_stats.total_bytes_billed) / POW(2, 40) AS tib_billed, -- conversion des bytes en TiB
(SUM(bq_stats.total_bytes_billed) * 6.25) / POW(2, 40) AS cost_usd -- calcul du coûtFROM model_executions me
LEFT JOIN bq_stats
ON bq_stats.node_id = me.node_id
AND me.compile_started_at <= bq_stats.start_time
AND me.query_completed_at >= bq_stats.end_time
GROUP BY
me.model_execution_id,
me.command_invocation_id,
me.run_started_at,
me.was_full_refresh,
me.thread_id,
me.status,
me.compile_started_at,
me.query_completed_at,
me.total_node_runtime,
me.rows_affected,
me.bytes_processed,
me.materialization,
me.schema,
me.name,
me.alias,
me.message,
me.is_last_invocation
)
SELECT * FROM final_result;
Nous avons maintenant une estimation de coût beaucoup plus fiable pour l'exécution des modèles dbt ! 🚀
Attention : cette estimation ne prend pas en compte les coûts de stockage BigQuery. Pour cela, il serait possible d'utiliser la table
TABLE_STORAGE, qui contient toutes les informations nécessaires. Cette donnée est également très intéressante, mais elle ne sera pas ajoutée dans cet article.
Prochaines améliorations du dashboard
Il y a encore beaucoup d'améliorations que je souhaite apporter à ce dashboard :
✅ Ajout des résultats des tests
✅ Détection d'anomalies
✅ Filtres plus fins (par exposure, par sources utilisées, etc.)
... et bien d'autres !
À bientôt pour de futurs articles ! 🚀