
On me demande souvent : « Cet outil a-t-il sa place dans ma stack data ? »
Pour répondre à cette question, je vous propose aujourd’hui un panorama des briques essentielles qui, selon moi, composent une infrastructure data moderne, fiable et capable d’évoluer avec votre entreprise.
Cet article s’adresse principalement aux organisations qui n’ont pas encore mis en place de véritable stack data, ou à celles qui sentent qu’il leur manque une ou plusieurs briques pour exploiter pleinement le potentiel de leurs données.
Je ne parle ici que d’outils que j’ai déjà utilisés, afin de m’assurer de leur pertinence et de vous donner un retour basé sur l’expérience.
Pourquoi moderniser sa gestion des données ?
Aujourd’hui, les entreprises doivent prendre des décisions de plus en plus rapides et précises. Pourtant, dans beaucoup de structures, les données sont encore :
- Éparpillées dans des fichiers Google Sheets ou Excel
- Consolidées manuellement à coups d’exports et de copier-coller
- Ou traitées via des processus opaques que seuls quelques initiés maîtrisent
Ce fonctionnement artisanal génère de nombreux coûts cachés :
- ⏳ Une perte de temps considérable
- ⚠️ Un risque accru d’erreurs
- ❌ Des décisions basées sur des informations incomplètes ou incorrectes
Moderniser sa stack data, c’est mettre en place une infrastructure qui :
- Centralise toutes les données dans un environnement fiable
- Automatise leur traitement pour réduire l’erreur humaine
- Améliore la qualité et la traçabilité
- Rend les équipes métiers plus autonomes
- Prépare le terrain pour l’IA et le machine learning
Bonne nouvelle : ces dernières années, de nombreux outils sont apparus pour nous aider à construire des stacks data efficaces, robustes et évolutives.
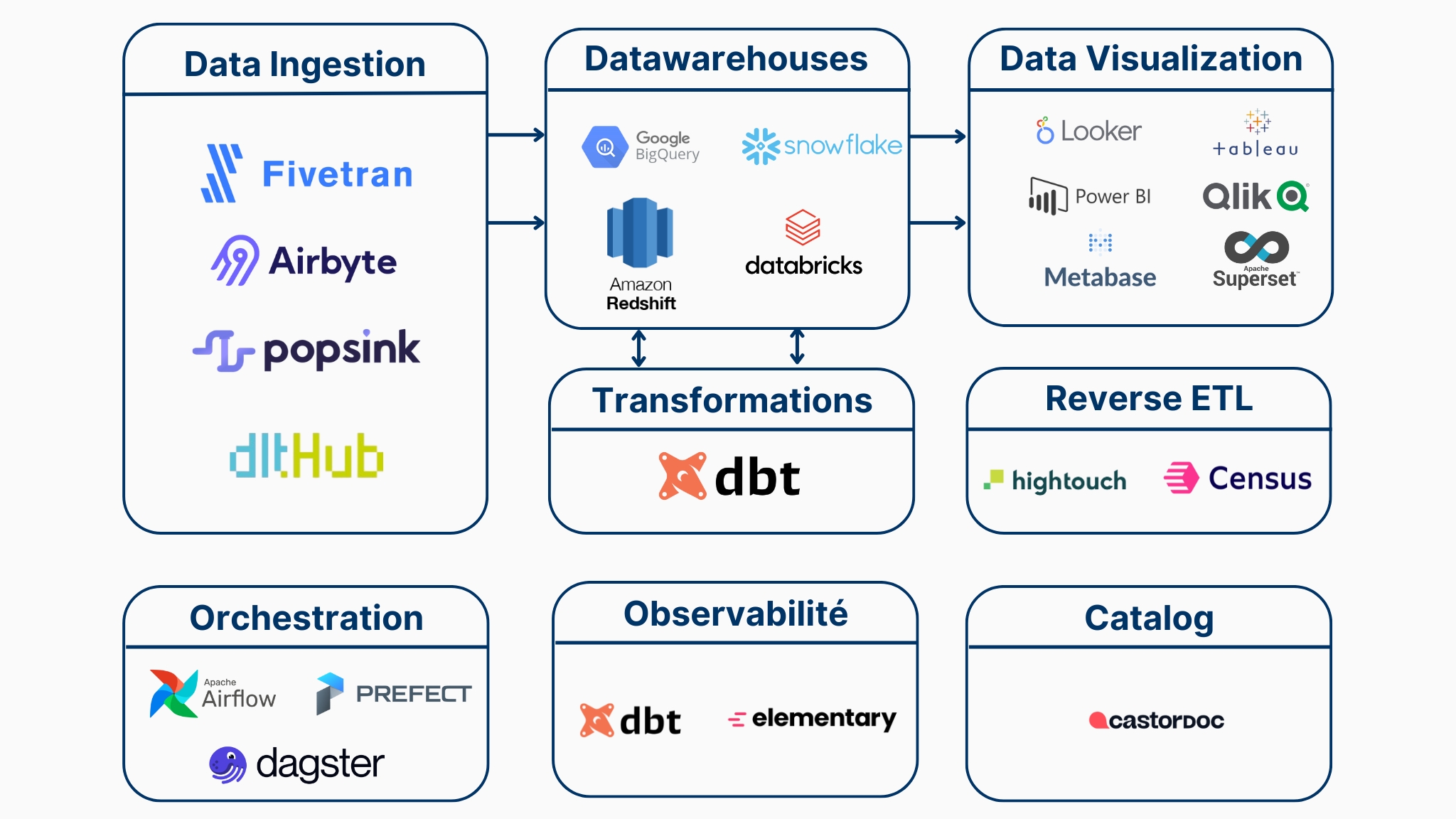
Les piliers d’une stack data moderne
Une architecture data efficace repose sur quatre piliers principaux :
- Ingestion : collecter automatiquement les données depuis toutes les sources
- Stockage : centraliser ces données dans un environnement performant
- Transformation : nettoyer, structurer et appliquer la logique métier
- Activation : mettre les données finales à disposition pour la prise de décision
À ces piliers s’ajoutent trois briques transverses qui renforcent la solidité de la stack :
- Orchestration : coordonner et planifier les traitements
- Observabilité : garantir la qualité et la fraîcheur des données
- Catalogue & gouvernance : documenter et faciliter la découverte
🔄 1. Ingestion et extraction de données
Objectif : extraire et synchroniser toutes vos données sources pour les stocker et les transformer.
Certains outils se branchent directement sur vos systèmes, d’autres demandent plus de développement pour construire des connecteurs personnalisés. Cela a un impact direct sur le coût et la maintenance.
Fivetran
Fivetran est le leader de l’ingestion automatisée. Simplicité, fiabilité et connecteurs maintenus en permanence : vous configurez, et ça tourne.
✅ Idéal pour les entreprises cherchant une solution clé en main et très fiable
❌ Peut devenir coûteux avec de gros volumes

Airbyte
Alternative open source à Fivetran. Très flexible, permet de créer ses propres connecteurs, mais nécessite plus de supervision.
Avec le temps, j’ai tendance à le recommander moins souvent en raison de problèmes de fiabilité. Mais certains de mes clients en sont satisfaits, donc je le mentionne ici.
✅ Réduction des coûts, contrôle total
❌ Connecteurs parfois instables, support communautaire variable, maintenance plus lourde
Popsink
Outil spécialisé dans le temps réel. Idéal pour le suivi de transactions e-commerce, l’IoT ou la détection de fraude.
✅ Parfait pour les cas d’usage où la fraîcheur des données est critique
❌ Coût plus élevé et complexité accrue des projets temps réel
dlt (Data Load Tool)
Librairie Python open source pour construire ses pipelines d’ingestion et ELT sur mesure.
Article conseillé : dltHub : une alternative Python-first à Fivetran et Airbyte
✅ Très souple, approche code-first, coûts maîtrisés
❌ Nécessite une équipe technique pour la mise en place et la maintenance
🧠 2. Transformation des données
Objectif : donner du sens métier aux données en les nettoyant, en les structurant et en les liant entre elles.
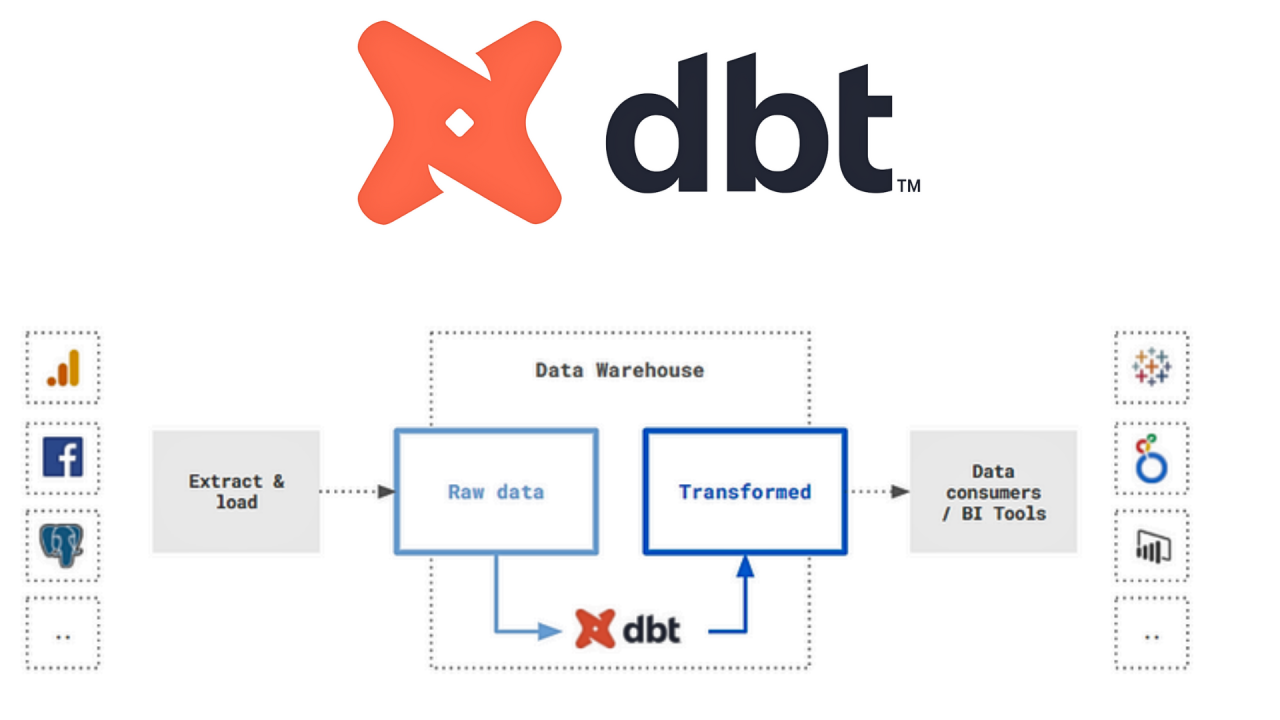
dbt (Data Build Tool)
Incontournable aujourd’hui, dbt permet d’écrire ses transformations en SQL tout en intégrant les bonnes pratiques du développement logiciel : versioning, modularité, tests.
En 2025, dbt Fusion améliore encore l’expérience développeur grâce à son nouveau moteur en Rust.
Article conseillé : dbt Fusion : qu'est-ce que c'est ?
✅ Clarté et robustesse des projets
❌ Nécessite une modélisation solide pour être pleinement efficace
À noter : Fivetran a récemment acquis SQLMesh, un concurrent direct de dbt. Je suivrai son évolution et vous en reparlerai dans un prochain article.
🗃 3. Stockage et moteurs de requêtes
Objectif : rassembler toutes vos données au même endroit pour pouvoir les analyser facilement et rapidement, sans dépendre de dizaines de fichiers éparpillés.
BigQuery (Google Cloud)
✅ Très simple à utiliser, pas besoin de gérer de serveurs, s’adapte automatiquement à vos besoins
❌ Facturation à la requête : peut devenir cher si vous lancez beaucoup d’analyses
Snowflake
✅ Chaque équipe peut analyser les données sans ralentir les autres, fonctionne sur tous les grands clouds
❌ Peut vite coûter cher si la consommation n’est pas surveillée
Databricks SQL
✅ Permet de faire à la fois du reporting classique et de l’intelligence artificielle sur les mêmes données
❌ Plus complexe à prendre en main, souvent utilisé par des équipes data déjà expérimentées
Amazon Redshift (Serverless / RA3)
✅ Bien intégré si vous utilisez déjà AWS, offre une version « sans serveur » qui s’adapte automatiquement à vos besoins
❌ Moins flexible que BigQuery ou Snowflake pour les montées en charge rapides
📊 4. Activation des données
Objectif : tirer de la valeur de vos données. Une fois stockées et transformées, elles doivent être utilisées concrètement pour :
- Créer des tableaux de bord clairs pour piloter votre activité
- Automatiser certaines actions operationelles (ex : envoyer une campagne marketing ciblée)
- Préparer des modèles prédictifs (ex : identifier les clients à risque de départ)
Tableau / Power BI / Looker / Qlik
✅ Outils de référence pour créer des tableaux de bord et suivre vos indicateurs en temps réel
❌ Licences payantes et besoin de formation pour bien exploiter toutes les fonctionnalités
Metabase / Superset
✅ Alternatives open source, économiques, utiles pour des besoins simples de reporting
❌ Moins adaptés si vous avez beaucoup d’équipes ou des besoins de gouvernance avancée
Hightouch / Census
✅ Permettent de renvoyer vos données enrichies (ex : scores clients) directement dans vos outils métiers (CRM, emailing, support…)
❌ Peuvent complexifier votre stack si mal utilisés
Dataiku
✅ Plateforme qui ajoute une brique d’intelligence artificielle (prévisions, recommandations, automatisations) sur vos données
❌ Plus coûteux et nécessite une équipe data pour en tirer tout le potentiel
🧩 5. Orchestration
Objectif : coordonner l’exécution des pipelines. Utile quand la stack devient complexe, mais optionnel dans les débuts d’un projet de mis en place de stack Data.
- Airflow : robuste et standard de l’industrie, mais complexe.
- Dagster : plus moderne, avec typage fort et meilleure visibilité.
- Prefect 2.0 : workflows dynamiques, API-first, plus accessible.
🔍 6. Observabilité et qualité des données
Objectif : s’assurer de la fiabilité, fraîcheur et disponibilité des données, pour que les décisions reposent sur des informations correctes.
- dbt Tests + dbt-expectations : intégrés à dbt, versionnés avec le code.
- Elementary : rapide à mettre en place pour monitorer un projet dbt.
Article conseillé : dbt-elementary : Le package dbt pour maintenir une bonne Data Quality
🧭 7. Catalogue et gouvernance
CastorDoc
Permet de documenter les jeux de données, de visualiser le lignage et d’aider les utilisateurs à comprendre et exploiter les informations disponibles.
✅ Interface moderne et intuitive, documentation collaborative, lignage automatique
❌ Solution récente, moins d’intégrations que les leaders du marché
Conclusion
En 2025, moderniser une stack data ne consiste pas seulement à choisir de bons outils : l’enjeu est de les assembler intelligemment pour répondre à vos besoins métiers.
Concrètement, cela signifie :
- Moins de temps perdu à consolider des fichiers Excel et à chercher l’information
- Des décisions plus fiables, basées sur des chiffres à jour et vérifiés
- Une meilleure visibilité sur votre activité (CA, marge, churn, coûts d’acquisition, etc.)
- Un terrain prêt pour l’avenir : IA, automatisation, personnalisation client
C’est exactement ce que je fais en tant que freelance : j’aide les entreprises à passer d’un fonctionnement artisanal de la donnée à une infrastructure moderne, robuste et adaptée à leurs besoins.
Si aujourd’hui vos données sont dispersées, peu fiables, ou simplement sous-exploitées, contactez-moi.
Je peux vous proposer un premier diagnostic gratuit pour identifier vos priorités et vous montrer comment une stack data moderne peut transformer votre pilotage et vos résultats.